DeepSeek火爆出圈,各大第三方紧赶慢赶纷纷接入,已经成为现象级议题。
但当话题最热点过去,回归到实际落地这个关键上,新的问题正在进入到一线从业者的视野之中——
怎样才能简单、高效用好DeepSeek?
核心在于,对于企业用户,尤其是更多来自传统行业的企业而言,在自身业务中引入推理模型,不是简简单单接个API的事,要想用得好,还得结合本地数据、业务场景。
这也就意味着几方面的困难,包括但不限于,算力基础设施的建设和管理、支持大规模在线业务的性能优化以及数据的安全合规问题……

就在本周,DeepSeek官方也开始围绕AI Infra,连续开源内部秘籍,对于模型从业者们自是喜大普奔,在产业结合层面却有点“远水解不了近渴”。
好消息是,云厂商们已经第一时间出手。
就在这个关口,火山引擎正式发布AI一体机,推出更高性能优化、更全产品能力和更好安全防护的一站式解决方案,目标很明确:帮助用户在大模型应用领域,低门槛地实现创新技术探索和业务增长。
本次发布,还有专门的DeepSeek版本,支持DeepSeek R1/V3全系列模型,开箱即用,小时级就能完成部署。

DeepSeek应用端到端解决方案
所谓“AI一体机”,简单来说,就是把人工智能所需的硬件和软件“打包”在一个设备里,让用户无需繁琐的安装、配置,就能直接使用的一种“AI专用终端”。
以火山引擎AI一体机-DeepSeek版为例,通过支持DeepSeek R1/V3全系列模型,以及火山引擎自家HiAgent智能体平台、大模型防火墙和轻量模型训练平台,实现了对模型部署、管理、推理、微调、蒸馏以及AI应用开发的全链路能力覆盖。

△火山引擎AI一体机-DeepSeek版产品架构
具体来说,火山引擎AI一体机-DeepSeek版具备以下特点:
开箱即用,无需复杂配置,无需依赖外部环境,小时级就能完成部署,快速体验完整服务。
轻量起步,采用轻量云原生架构,仅需1台GPU服务器即可部署,3台节点即可实现高可用生产环境。
一站式体验,集成主流开源模型、豆包大模型,涵盖底层基础设施、企业级模型服务平台(MaaS)、智能体开发(HiAgent),提供模型调用、部署、精调、测评、应用开发调优等全方位功能。
软硬件协同,深度优化DeepSeek全系列模型,通过火山引擎自研通信库veCCL、推理引擎、算子优化及高性能KV Cache等全链路技术,核心推理性能提升20%以上。
安全高效,提供100+行业应用模板和100+适配插件,支持企业通过自身工作流自定义专属AI,同时集成大模型防火墙和AI网关,满足安全与合规需求,打通从模型到应用的“最后一公里”。
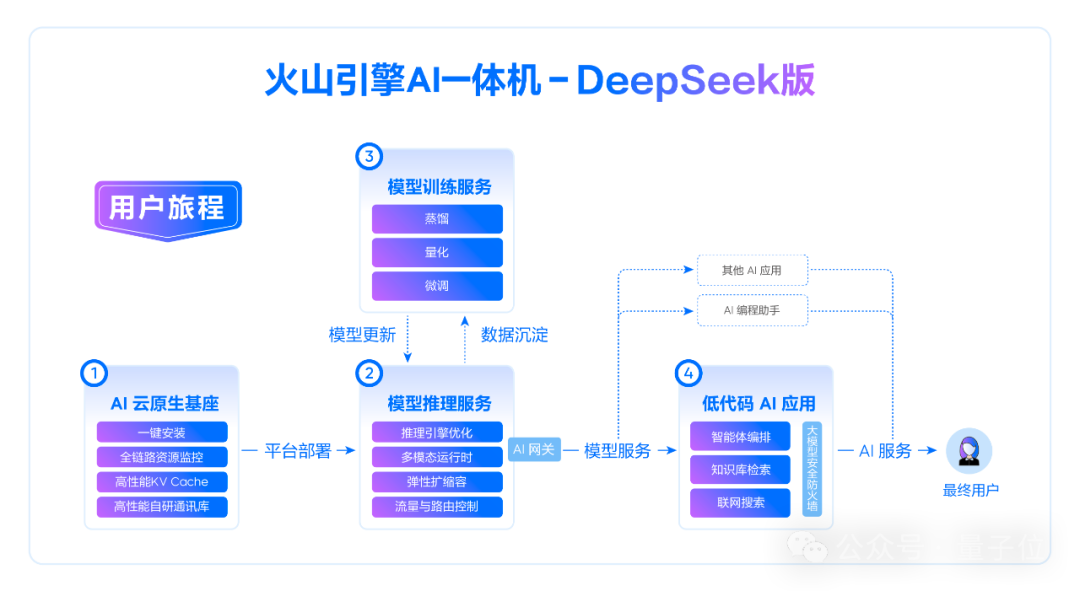
分析其中技术组成,可以看到火山引擎AI一体机主要解决的是3个方面的问题。
首先,是基础设施优化和平台运维。
传统的软硬件系统,软件和硬件相对独立,往往缺少软硬件协同优化,因而影响系统运行效率。
另外,也经常会因为监控和运维系统不到位,导致系统经常出现各种不稳定的情况。
而火山引擎AI一体机基于AI云原生基座,在基础设施层面,提供了分布式缓存、集合通信优化、软硬件协同的资源调度等能力。
在平台运维层面,则通过一键部署、水平扩容、平滑升级、监控告警等能力,为平台稳定运行提供保障。
其次,是推理模型的实际部署。
以DeepSeek为例,尽管是开源模型,但从模型本身到上线生产环境,实际还要面临许多诸如优化、稳定保障、合规检查的工程问题。
火山引擎AI一体机通过内置DeepSeek等开源模型,为模型提供优化的推理引擎、分布式缓存和高效的路由能力,能降低Token延时,最大化模型服务吞吐量。
同时也为推理服务提供授权、观测、弹性和流量治理能力,保障推理服务可靠、高效、稳定运行。
最后,是模型迭代和AI应用开发。
无论是结合自身业务数据,精调基础模型,还是根据业务需要,开发AI应用,都仍是需要大量技术投入的过程。
而很多行业用户往往存在专业人才不足、开发效率低的问题。
火山引擎AI一体机从模型调用到应用开发的一站式工具集成,提供包括任务管理、低代码开发、灵活集成方式和大模型安全等全方位辅助,可以说是有效降低了企业的应用门槛和开发成本。
大模型应用经验加持
在“DeepSeek”这个热点之外,值得关注的是,火山引擎此番推出AI一体机,不仅是给企业“拥抱”DeepSeek等开源模型铺了条快速路,背后还有火山引擎在大模型应用开发和市场领域积攒的经验加持。
更高性能优化
展开更多细节来看,性能优化方面,不同于市场上大多数基于INT8精度的DeepSeek解决方案,火山AI一体机支持DeepSeek官方推荐的FP8精度。
同时还进行了基础架构和推理引擎的优化。
比如,在大模型服务启动方面,70B模型启动通过高性能缓存加载,模型加载速度相比本地盘提升10倍。推理服务采用按需加载,服务启动时间提升4倍。
通过开源算子优化,如flashattention v3算子优化,可以在部分配置硬件上将主流模型吞吐量提升10%。
高性能KV Cache缓存支持Automatic Prefix Cache,能有效提升大模型长上下文记忆能力。火山引擎透露,在内部环境测试中得到了以下结果:
- 提升大模型长记忆力能力,50% Cache场景下,吞吐量提高1倍以上;
- multi-node共享高性能KV Cache缓存,支持GPU节点无状态快速扩缩。
针对单机多卡和多机多卡的模型推理和训练场景,火山引擎还在NCCL的基础上自研veCCL集合通讯库。在多卡推理TP场景,能将核心推理指标提升5%。
更全产品能力
产品能力方面,火山引擎AI一体机集成了火山方舟的同源能力,支持模型精调、推理、测评全方位功能和服务。
不仅能单机8卡部署满血DeepSeek等开源模型,预置联网搜索等100+插件和海量行业应用模板,提供零代码、低代码的分钟级AI应用构建。
算力方面,还全面兼容英伟达GPU及国产异构计算卡,满足多样化算力需求。在模型官方推荐精度下,无论是在推理还是训练任务中,均能实现高效稳定的性能表现,兼顾模型精度和计算效率。
更好安全防护
内容合规和数据安全方面,火山引擎AI一体机引入了自研大模型应用防火墙。
在DeepSeek R1/V3上的测试结果显示,接入大模型应用防火墙后,DeepSeek R1的有害内容生成率从9.1%下降到了0.91%;DeepSeek V3的有害内容生成率从17.3%下降到了2.7%。
大模型应用防火墙同样能降低数据泄露风险,防御提示词注入攻击等安全威胁。在DeepSeek R1/V3上的测试结果显示,接入大模型应用防火墙,针对DeepSeek R1的提示词攻击成功率从76%下降到1%,针对DeepSeek V3的攻击成功率从大于24%下降到小于1%。
大模型应用防火墙还能使特定知识所涉及的模型幻觉现象减少90%以上。

当新技术突破激发的肾上腺素逐渐消退,DeepSeek引发的讨论和思考,正在逐渐走向第二阶段:
从跟风热议,到更加务实的落地探索。
或许不似模型突破本身那样有话题性,却意味着大模型技术更深更长远的影响已经被纳入思考和实践。
DeepSeek这尾鲶鱼搅动风云,向全球大模型研发者们提出新的挑战,与此同时,也正在激发行业更深的思索和技术融合。
谁能把握住机会?火山引擎已经率先迈步。
来源:微信公众号“量子位”