就在18号,被马斯克狂吹为“地球上最聪明AI”的Grok 3聊天机器人现世了。
马斯克携手xAI(其投资创建的AI企业)的工程师们通过直播的形式,向世界展示了Grok 3的实力——在减少AI幻觉、提升逻辑一致性、联网获取实时信息以及深度搜索等方面,Grok 3都展现出了可能超越OpenAI和DeepSeek等大模型的能力。
马斯克在发布会上激动地说,Grok 3的能力相比其前身Grok 2,强大了一个数量级。这番言论,让Grok 3迅速成为全球科技与资本市场的热门话题。
而且马斯克还为Grok3整了一个更有逼格的定位:“our mission is to understand universe(我们的使命是了解宇宙)”。

而迅速推出Grok 3的背后,也藏着马斯克与阿尔特曼(OpenAI创始人)之间的复杂恩怨。两人曾携手创立OpenAI,誓言用开源技术挑战谷歌的AI霸权。可如今两人却分道扬镳,甚至在某些场合针锋相对,上演了一出出“背叛”与“反击”的戏码。
那么,这个由马斯克倾尽心血的Grok 3,能否让马斯克在阿尔特曼面前争一口气?它是否能够重塑AI聊天机器人的格局?而资本市场又是否会给予它足够的支持呢?
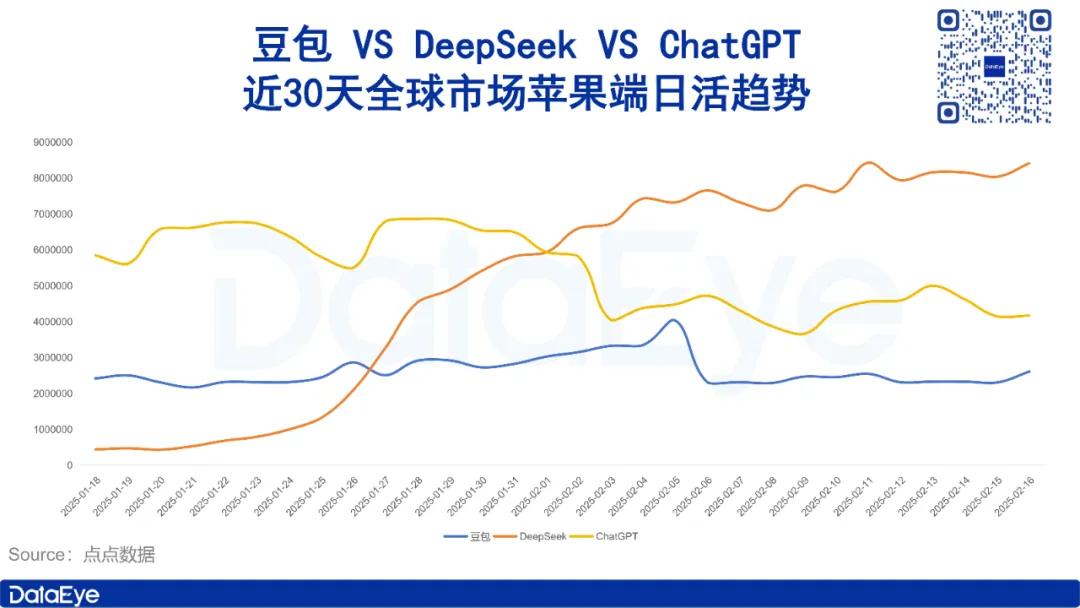
Grok3超越DeepSeek和ChatGPT?
美国科幻大师罗伯特·海因莱因的小说《异乡异客》中,有一位在火星上长大的角色叫作“Grok”,它代表了对某事物全面且透彻的理解。

马斯克表示,xAI 团队之所以将其聊天机器人命名为Grok就是源于这个初衷。
作为xAI正在精心打磨的杰作,Grok 3最引以为傲的便是突破性的“思维链”推理能力和多模态功能的全面升级。
虽然Grok 3是一款聊天机器人,但其“推理”能力却不容小觑。它不仅能与用户进行流畅的自然语言互动,更能逻辑性地测试其响应并进行严格的事实核查。
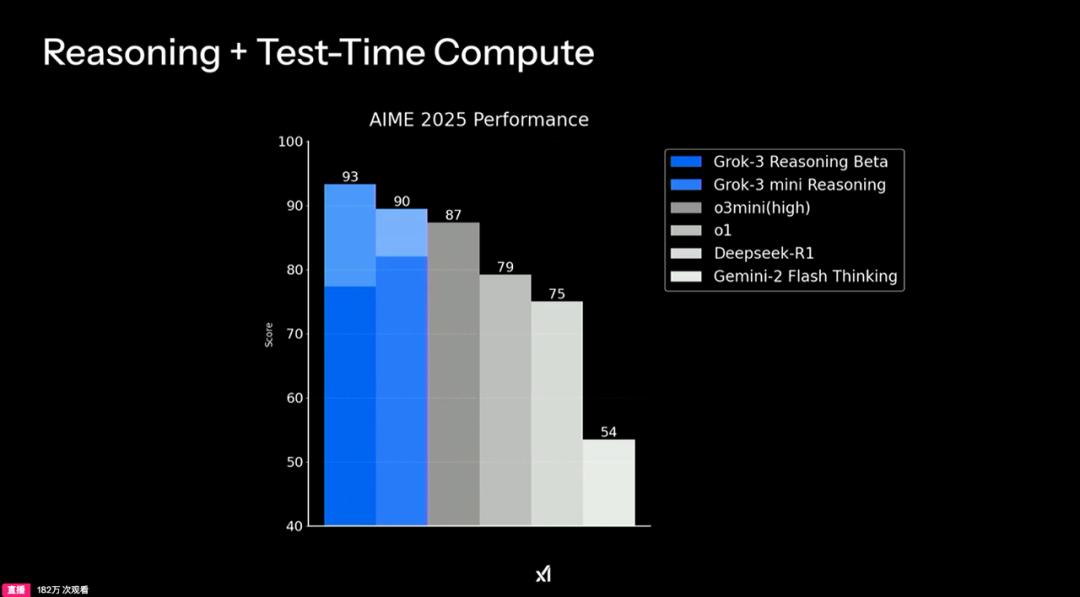
马斯克和他的团队自豪地宣布,Grok 3测试版的推理能力甚至可能已经超越了现有的众多人工智能模型。在关于推理和测试时间的基准测试中,Grok 3以卓越的表现,力压DeepSeek-R1、OpenAI o1、OpenAI o3 mini-high以及Gemini-2 Flash Thinking等一众强敌,展现了其非凡的实力。
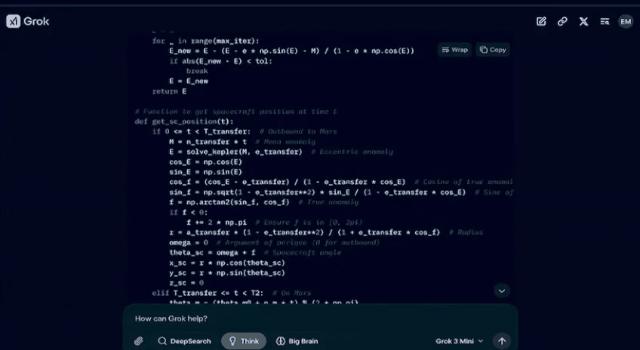
xAI团队还通过一系列有趣的展示,让我们亲眼见证了Grok 3的过人之处。比如,在计算从地球到火星的航天器任务时,Grok 3竟然能够生成一张生动的太空发射动画3D轨迹图,从地球出发,穿越火星,再返回地球,这一过程中涉及的复杂物理知识,都被它一一攻克。
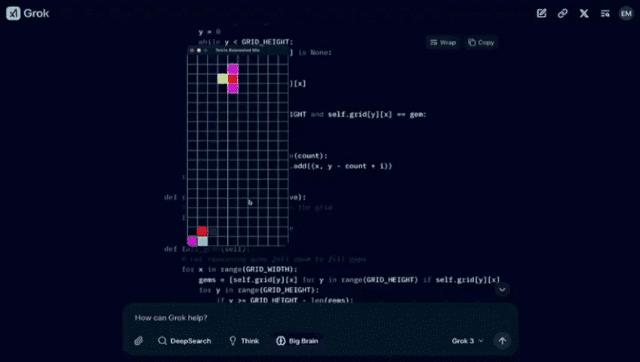
更令人惊叹的是,Grok 3还足够聪明,能够根据超强的推理能力编写游戏或结合现有游戏。当xAI团队要求Grok 3现场创造一款融合《俄罗斯方块》和《宝石迷阵》的新游戏时,它迅速生成了一个Python脚本,定义了游戏的常量、颜色、方块形状等元素,并创造出了一种独特的玩法:当连接了至少三个相同颜色的方块时,会触发重力机制使方块消除。
而Grok 3的多模态功能升级,更是让人眼前一亮。它并非单一的模型,而是一个由多个模型组成的家族。其中,轻量级版本Grok 3 mini主打实时响应,推理速度较标准版提升了惊人的5倍;而Grok 3 Reasoning则采用了类人脑的“慢思考”机制,通过多层事实核查,有效规避了AI幻觉的问题。
在数学推理、代码生成和科学逻辑测试中,Grok 3的表现同样令人瞩目,它超越了Gemini 2 Pro、Deepseek V3、ChatGPT 4o等竞品,展现出了强大的竞争力。

在盲测方面,xAI的Grok 3(早期版本)更是以1402分的历史最高成绩,在lmArena排行榜上登顶,成为首个突破1400分的AI模型,这一成绩甚至超越了Google、OpenAI、DeepSeek等业界巨头。
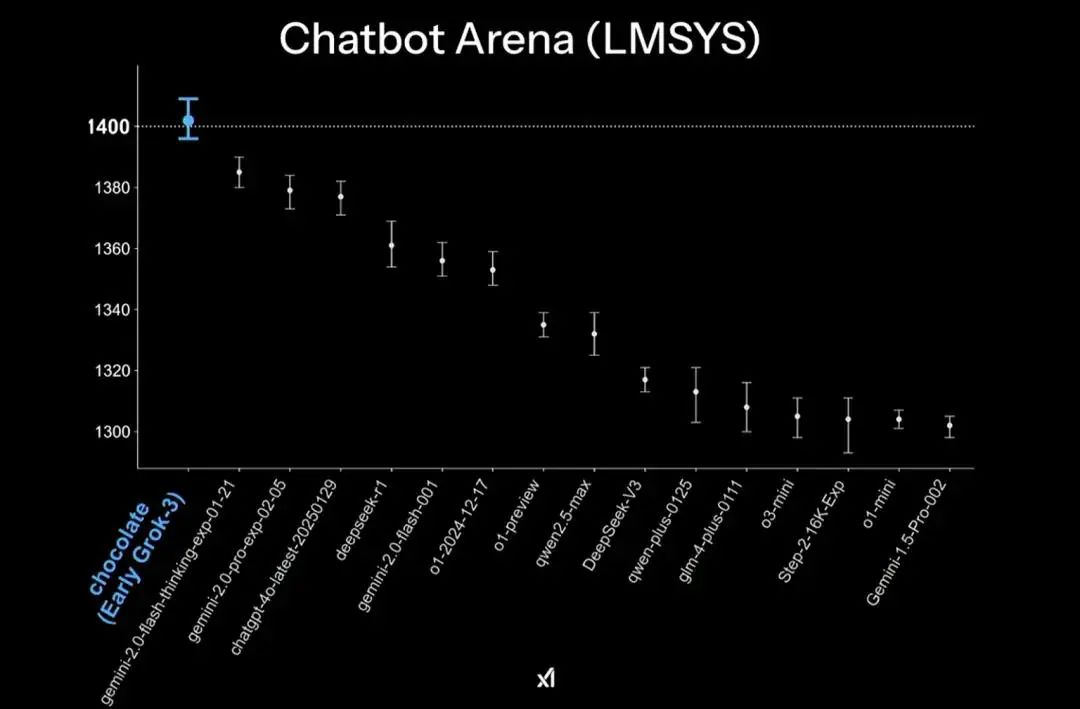
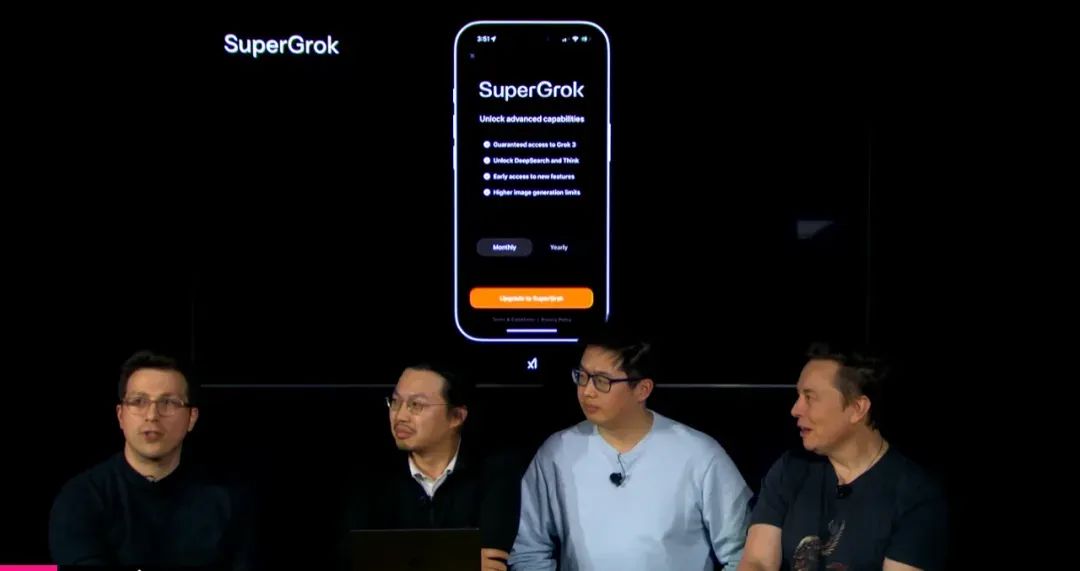
值得注意的是,马斯克团队仍在持续优化Grok 3的能力,Grok 3目前仅对X Premium Plus订阅用户开放,但xAI为忠实粉丝推出了名为Super Grok的独立订阅服务,提供最先进的功能和最早的新特性访问权限。
此外,xAI还推出了SuperGrok计划,订阅用户能够访问更多推理能力和无限图像生成。并计划未来数周内上线语音模式及企业API接口。
那么被马斯克吹上天的Grok3是如何炼出来的呢?
122天,马斯克用20万块GPU张大力出奇迹
有句说句,Grok 3能迅速发展,离不开xAI的惊人的工程执行力。
xAI高管团队透露,为实现“打造顶尖AI”的目标,公司选择自建数据中心作为核心路径。
第一阶段,他们仅用122天便完成10万块H100 GPU集群部署,建成当时全球最大规模的全连接算力基础设施。
第二阶段进一步提速,仅92天就实现算力翻倍,使集群规模达到20万块GPU——这些硬件资源全部投入“科洛苏斯超级集群孟菲斯数据中心”,成为训练Grok 3的核心支撑。

技术突破方面,xAI通过大量使用合成数据等创新手段,使Grok 3相较前代实现10倍计算能力跃升,以超快的速度追上了ChatGPT。
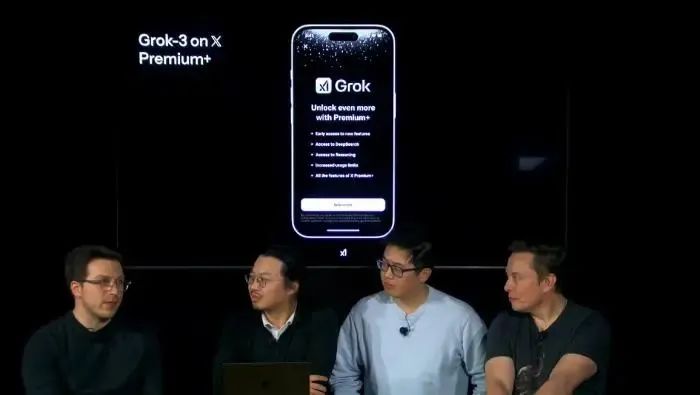
在配套生态的构建上,xAI同样不遗余力。他们推出的DeepSearch被誉为“下一代搜索引擎”,它允许用户提问并获得答案,更重要的是,DeepSearch能够展示从问题思考到研究,再到最终答案生成的完整过程。
DeepSearch是一款推理聊天机器人,能够阐述其理解查询内容的过程以及规划回复的方式。在演示中,DeepSearch展现出了研究、头脑风暴和数据分析等多种功能,令人眼前一亮。
对于Grok 3是否会开源,马斯克明确表示,“我们通常会在新模型发布的时候,开源上一代模型,所以几个月后,我们也会对Grok 2进行开源。”

这种“代际开源”策略既保持了技术护城河,又满足了开源社区的期待,不少网友认为马斯克格局不错,但也留着底牌。
资本市场对此次技术突破反应热烈。
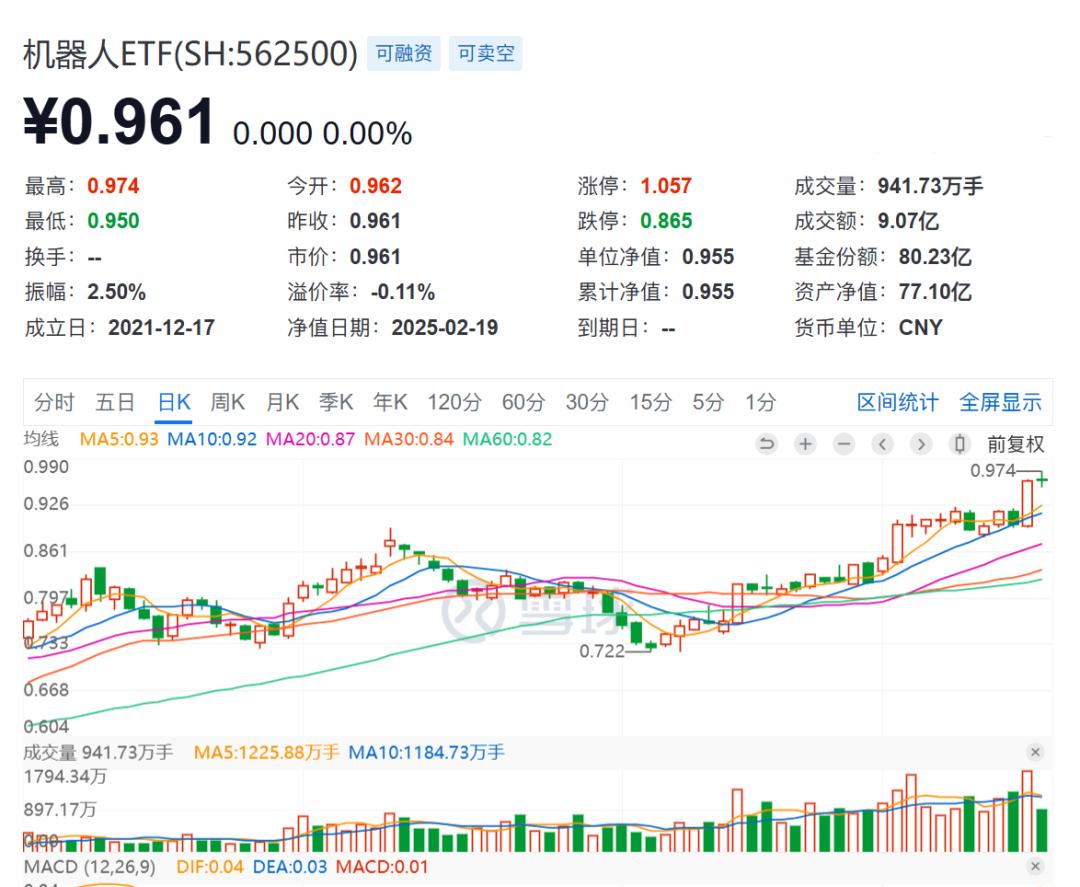
Grok 3发布当日,恒生互联网科技业指数开盘冲高1.8%,恒生互联网ETF(159688)收涨1.42%,金山云、腾讯控股等AI概念股集体跟涨。更显著的是机器人ETF单日资金净流入突破十亿元,创历史纪录。
投资机构层面,Grok 3发布会后,红杉资本、Andreessen Horowitz等顶级风投加速入场,推动xAI融资规模剑指百亿美元,公司估值飙升至750亿美元。
不过相较于OpenAI的3000亿估值,Grok 3还差一些。市场仍认为xAI在生态壁垒和商业化成熟度上的优势仍不如OpenAI。
目前,Grok 3虽然仅通过一场直播demo曝光,没有更多官方信息,但其含金量几何,还需更多用户和时间验证。
不过,从Grok 3发布会背景板上的那句“our mission is to understand universe(我们的使命是了解宇宙)”可以看出,马斯克的野心远不止于此。
马斯克离“用AI理解宇宙本质”的终极目标还有多远?或许还要再等Grok 3再飞一会。
搞Grok3只为了赌气?阿尔特曼公开羞辱马斯克
不过,在Grok 3风靡全球的背后,一场不为人知的内部斗争同样引人入胜,主角便是曾经的盟友——埃隆·马斯克与山姆·阿尔特曼。

故事要追溯到2015年,硅谷的夜空下,马斯克与阿尔特曼携手启动了被誉为“AI曼哈顿计划”的OpenAI。
他们共同的敌人,是那时如日中天的谷歌,两人担忧其可能垄断AI技术,便牵头成立了非营利性质的OpenAI。
在阿尔特曼心中,马斯克一度是如“钢铁侠”般的存在,是打破美国科技僵局的英雄。然而,理想丰满,现实骨感。
随着OpenAI的算力成本飙升,财务困境如影随形。阿尔特曼做出了一个决定性的选择,引入微软10亿美元的投资,并成立了盈利性质的子公司OpenAI LP。

马斯克坚持非营利原则,认为这是对初衷的背叛,而阿尔特曼则认为商业化是生存之道。两人的分歧日益加深,马斯克认为OpenAI已沦为微软的“闭源附庸”,并试图夺回CEO之位,却遭到了董事会的拒绝。

阿尔特曼随即发起了内部斗争,成功争取到了另一位联合创始人格雷格·布罗克曼的支持,而布罗克曼又进一步拉拢了首席科学家伊利亚·苏茨克维尔站在自己一方。
2018年,马斯克黯然离场,阿尔特曼接掌了OpenAI的领导权。从此,两人分道扬镳,OpenAI也倒向了微软。
时间流转至2022年11月30日,ChatGPT横空出世,迅速成为21世纪最具影响力和变革性的科技产品之一,与iPhone、Facebook和TikTok并驾齐驱。

然而,对于马斯克而言,这款产品的问世却如同一把利刃,刺痛了他的心。作为曾经的创始人之一,他已被彻底排除在外,愤怒与失落交织于心。不甘心的他随即推出了自己的初创公司xAI,希望与ChatGPT一较高下。
法律战与舆论战也随之打响。马斯克连续起诉OpenAI“违背初心”,要求恢复开源,并批评其发展迅速却忽视安全。他在公开场合多次猛烈抨击阿尔特曼,而阿尔特曼也毫不示弱,两人的关系急剧恶化。
直到Stargate计划的公布,两人的矛盾被推向了顶点。阿尔特曼作为民主党人,却与特朗普政府合作推出了这个高达5000亿美元的人工智能基础设施投资项目,而马斯克却对此毫不知情。
可以说,Stargate计划不仅让马斯克感到被背叛,更打破了马斯克的政治与商业布局。
愤怒的马斯克随即发起恶意收购,愿意以974亿美元的价格收购OpenAI的控制权。而阿尔特曼的反击同样犀利,他嘲讽道:“我们愿以97.4亿美元收购Twitter。”阿尔特曼借此嘲讽马斯克以440亿收购Twitter的商业决策。
目前,两人的恩怨远没有结束,但唯一确定的是,Grok 3的出现已经让AI界再次沸腾了起来。
Grok 3的崛起,未来GPT5的发布,以DeepSeek为代表的中国AI军团的竞逐,无不预示着AI新时代的洪流滚滚,未来的路还很长,故事仍在继续。
参考资料:
1、《马斯克发布Grok 3大模型,称超越DeepSeek》澎湃新闻
2、《马斯克出手!Grok 3计算能力暴增10倍,谁才是最强大脑?》金十数据
3、《大力出奇迹?马斯克发布“史上最聪明AI”Grok-3,号称超越DeepSeek R1,20万张GPU能否颠覆AI格局?》金融界
来源:微信公众号“首席商业评论”