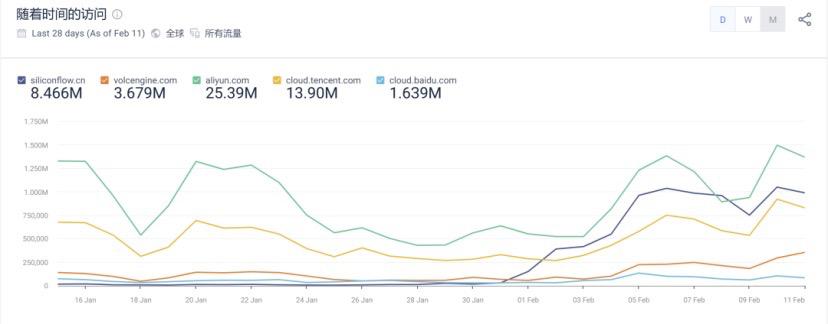
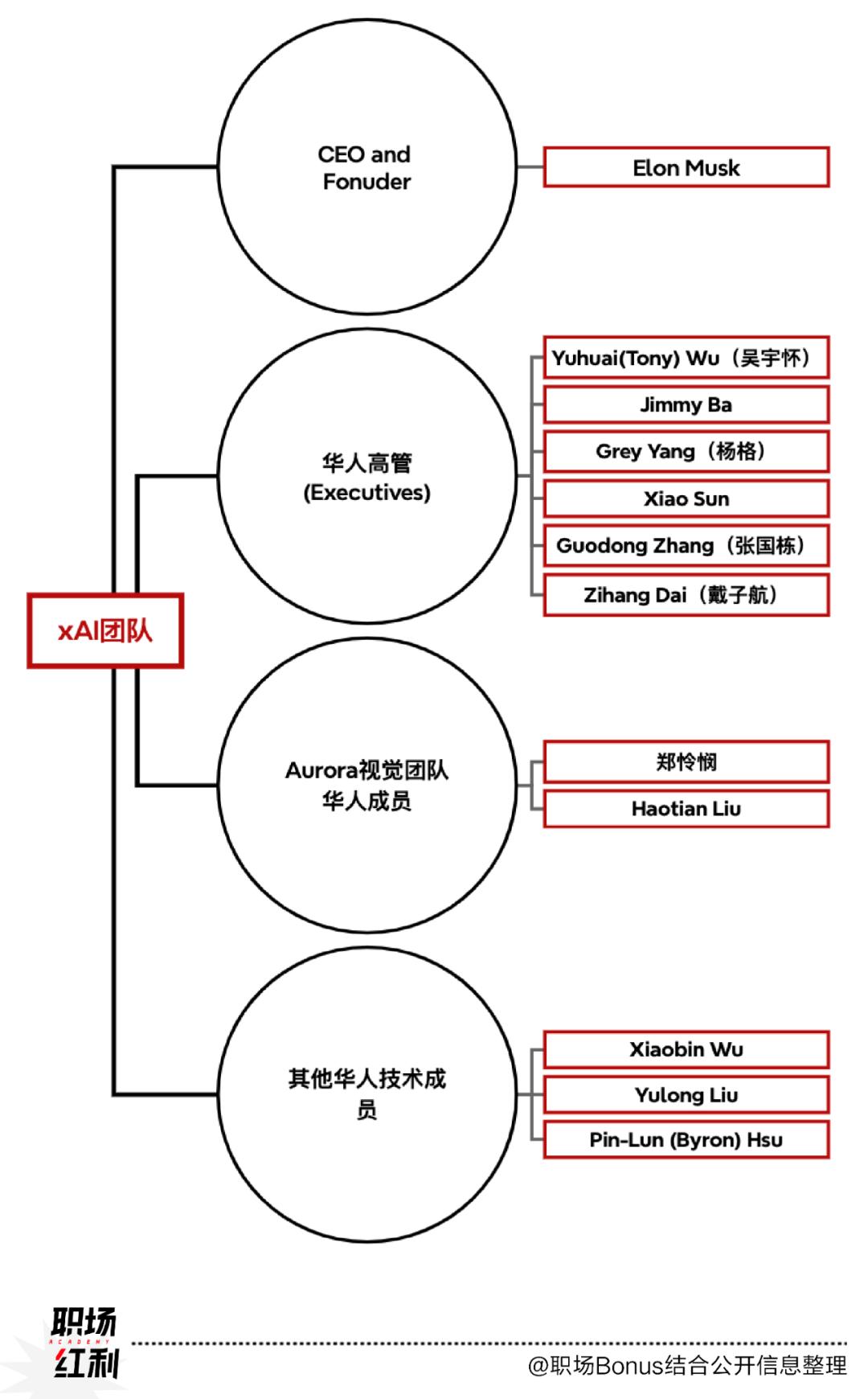
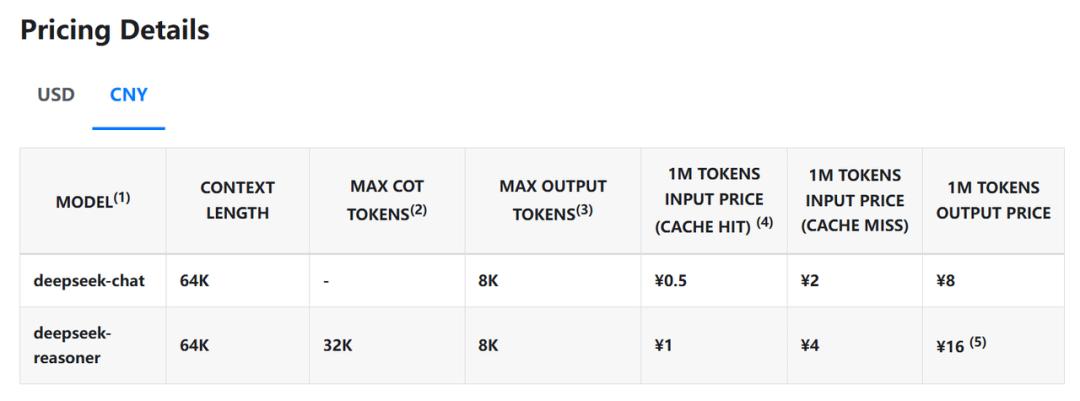
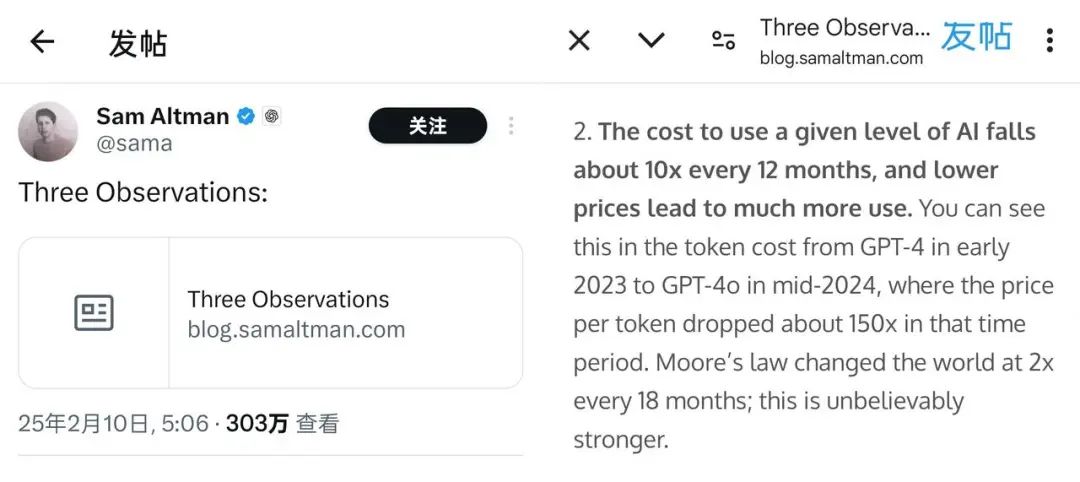
AI时代来临,最先爆发的可能是电力板块?
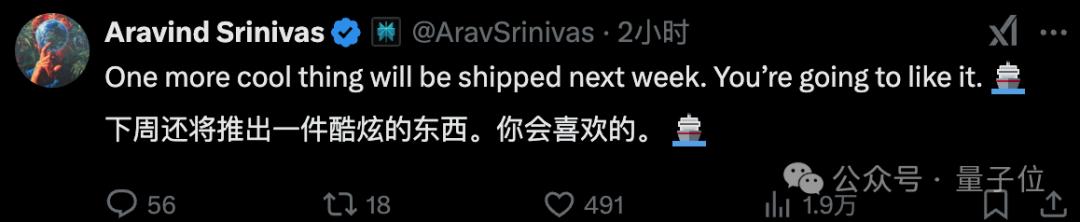
近期电力股股价持续上扬,国家电网、南方电网两大电网公司2024年投资6000亿元,创下新高,成为相关概念股股价坚挺的因素之一,同时中国制造提速和AI算力提升,尤其是近期DeepSeek大火,带动AI领域的火爆,对电力需求大增,供需端的巨大变化,让资本市场对电力系统持续看好。
国家电力系统在2024年交出了不俗的答卷,建成投运3项特高压工程,累计建成“22交16直”38项特高压工程,同时全年投产110千伏及以上线路4.38万公里,电网高质量发展进程全面加快。其中全年超6000亿元的投资,特高压交直流工程建设、电网数字化智能化升级等。
日前国家电网表示,2025年将进一步加大投资力度,投资金额将超过6500亿元,聚焦优化主电网、补强配电网、服务新能源高质量发展,推进重大项目。南方电网2025年将安排固定资产投资1750亿元,也将创下历史新高。
业内人士指出,电网投资是稳增长的重要方式,也是逆周期调节的重要环节,既能满足日益增长的电力需求,给产业链上下游企业带来发展机遇,又为跨省跨区电力交易提供保障,对建立全国统一电力市场发挥积极作用,同时为AI领域保驾护航,成为中国制造和中国智造重要推手。在投资金额大幅提升以及市场供需两旺的情况下,电力系统2025年或将迎来大爆发。
中美电力大比拼谁先慌了?
电力是一个国家和地区发展的晴雨表。我国在此前一直有“电力弱国”的标签,1989年,我国的发电总量方才达到美国1953年的标准,我国电力发展相较于美国存在较大的历史差距,人均用电量一度不到美国的十分之一。经过多年的发展,2003年我国发电量达到美国的一半。
中美科技战背后则是能源领域的比拼。为此新任美国专门成立了新能源委员会,旨在推动美国在人工智能领域的主导地位。而最近十余年中美电力地位的互换也成为中美经济发展的重要参考。
2011年,中国的年发电量达到47306亿千瓦时,首次成为全球最大的发电国家,发电装机容量也在这一年成为世界第一。
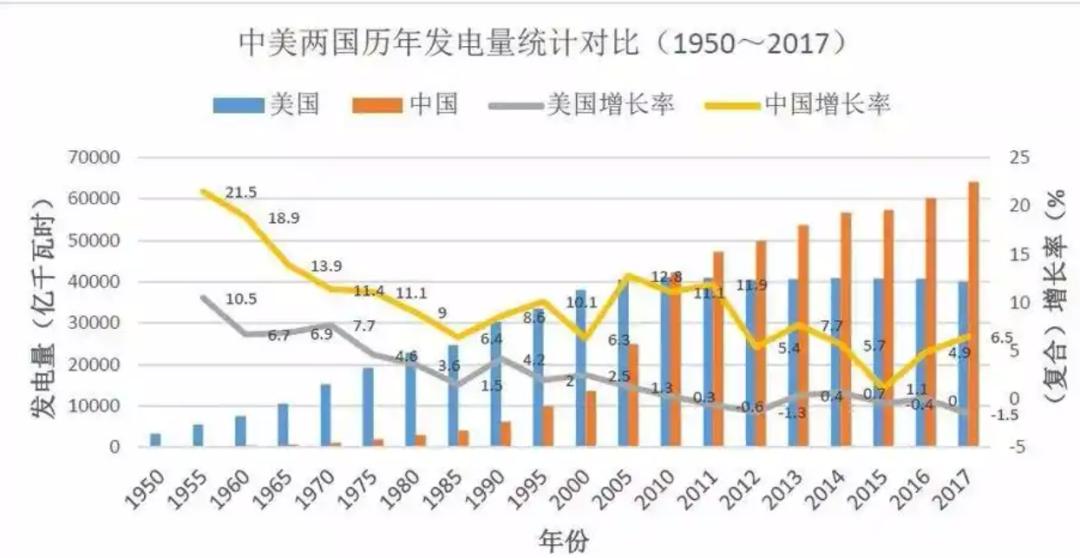
2014年,美国发电量为40935万千瓦时,同比增长0.7%。同期中国发电量为55495万千瓦时,同比增长3.8%。中国发电量是美国的1.36倍。这一年中国GDP为10.48万亿美元,美国GDP为17.61万亿美元,中国GDP为美国的59.5%。但在随后几年,中国的电力装机容量增长更快。2014年到2021年,中国建造的跨区域电网容量是美国的80倍。
当年美国的电力结构以天然气和其他气体发电为主,占比42.4%,其次是煤炭发电(27.8%)和核能发电(8.9%)。风能和光伏发电的增长显著,分别占比5.6%和0.9%。中国的电力结构虽然未具体提及,但中国的高效建设和快速能源生产速度表明其电力结构也在不断优化和现代化。
2024年,中国发电量为9.4亿千瓦时,美国总发电量为4.3亿千瓦时,中国发电量为美国的2.2倍。总装机量中国为26亿千瓦时,美国为13亿千瓦时,美国总装机量为中国的一半。
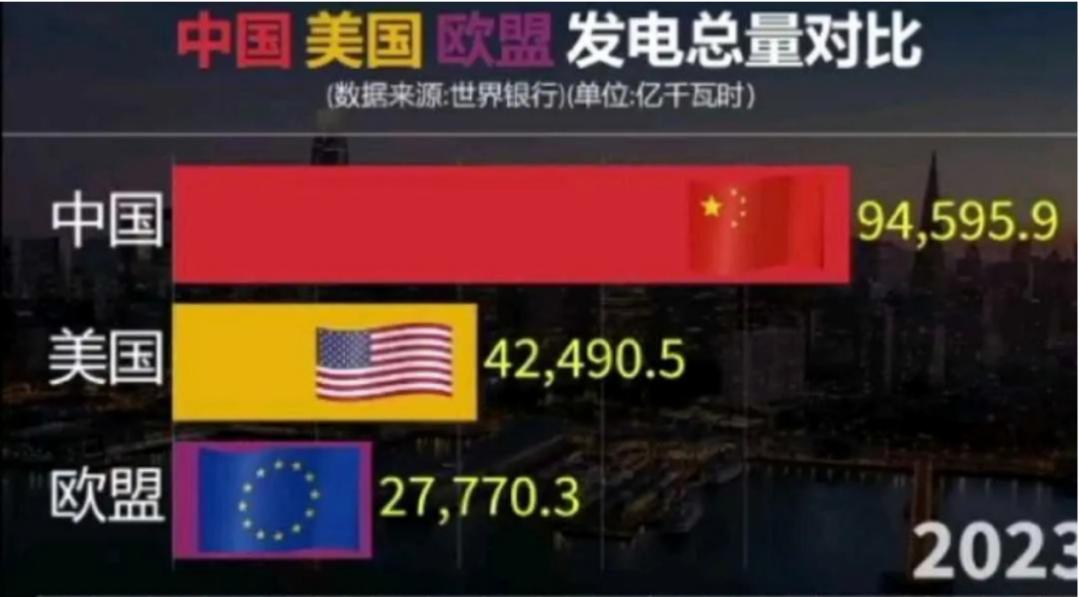
(中美以及欧盟2023年发电量对比)
2024年的数据显示,美国煤炭发电的比例仍占15%以上,甚至超过了所有可再生能源的总量。风电占11%,水电和太阳能加起来才10%。这样的比例远落后中国,中国的新能源发电比例接近50%,风电、光伏发电的利用率更是达到95%以上。中国的新能源不仅有规模,还有效率。2024年,全国新增发电量中,有近八成都来自可再生能源。
2024年美国GDP为29.2万亿美元,同比增长2.9%,中国GDP为18.94万亿美元,增速为5%。中国GDP是美国的65%,但除去汇率因素,真正差距并没有这么大。中国经济的迅速发展,以及缩小和美国的差距,电力功不可没。
没电力不算力
AI如今如火如荼,可很少有人知道AI算力需要海量的电力支撑,这个行业是不折不扣的耗电大户。数据显示全球数据中心的电力消耗约占全球总用电量的1%-2%。而随着AI算力需求的增加,这一比例预计将显著上升。
人工智能从业者王安然介绍称,AI算力的耗电量非常巨大,尤其是在训练和运行大规模深度学习模型时。随着AI模型的规模不断扩大(如GPT-3、GPT-4等),其对计算资源的需求呈指数级增长,从而导致电力消耗急剧上升。
“AI算力分为训练阶段和推理阶段,训练大规模AI模型需要大量的计算资源,通常使用高性能GPU或TPU集群。训练过程中需要反复迭代,计算量巨大,耗电量极高。训练GPT-3这样的模型可能需要数周甚至数月的时间,消耗数十万度电。推理阶段(即模型实际应用时)的计算量相对较小,但由于用户规模庞大,总体耗电量仍然很高。ChatGPT等AI应用每天处理数百万次请求,需要持续运行大量服务器。后期数据运营中心的计算设备、冷却系统以及相关网络设备都耗费大量电力。”王安然认为现阶段的AI算力能效很难降低,但降低能效是未来发展的必然趋势。
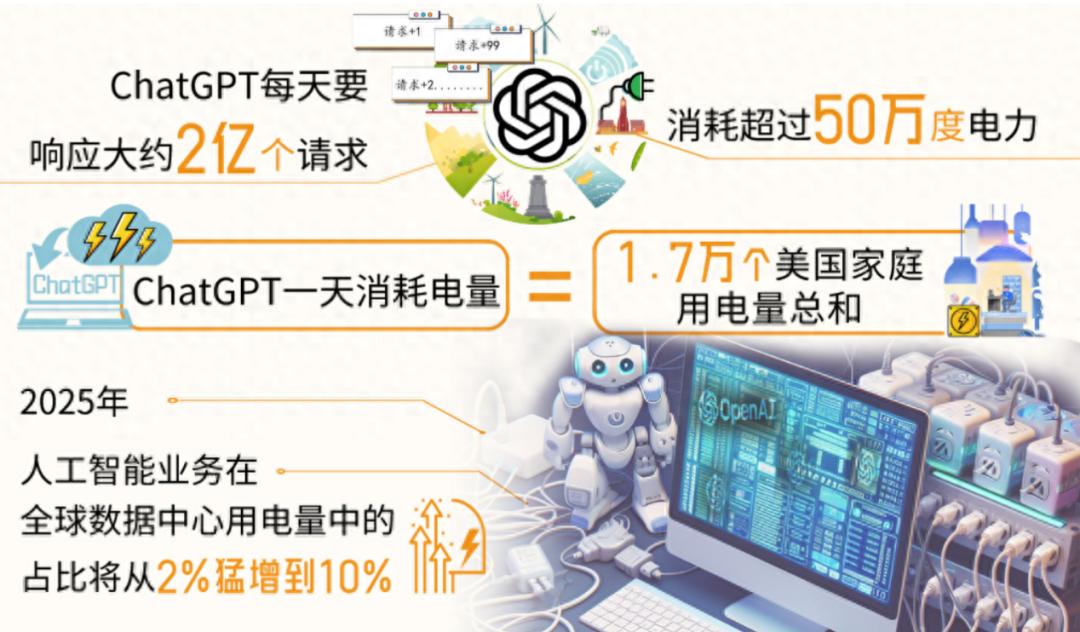
目前,GPT-3拥有1750亿参数,训练过程消耗了约1287兆瓦时(MWh) 的电力。这些电力足够121个美国家庭使用一年,ChatGPT一次训练造成相当于3000辆特斯拉电动汽车共同开跑、每辆车跑20万英里的耗电量。而GPT-4的规模更大,训练耗电量预计是GPT-3的数倍。
具体数据尚未公开,但估计可能需要数万兆瓦时的电力。ChatGPT的每个请求耗电约2.9瓦时,现阶段,ChatGPT每天需要响应1.95亿次请求,每天耗电约564兆瓦时,ChatGPT每天用电量相当于1.7万个美国家庭的用电量,是典型的电老虎。
“AI深度训练需要大量的数据输入,依赖于高端图形处理器(GPU)或定制的人工智能处理器来提升计算速度。数据量的增长直接导致计算任务的增加,使得这些高性能的计算组件消耗大量电能。大量的内存访问和计算操作也引发更高的能源消耗。”王安然解释了AI算力为何如此耗电。“降低能耗只能通过优化算法以减少计算需求、开发专门的AI芯片以提高能效、利用可再生能源为数据中心供电等。现阶段各家都在尝试,但效果并不明显。”
AI反哺电力
电力助力AI算力的发展,AI则反哺电力。通过AI算法可以在发电侧精准供需,智能发电控制系统能够精细调整发电机组的运行参数和优化控制策略,从而显著提升发电效率与系统稳定性。同时在电网侧实现风险管控。借助AI算法,智能电力调度系统能够实时监测电网运行状态并进行优化调度,确保电力供需始终保持平衡,同时提升整个电网的运作效率。在用人侧则实现了降本增效,大大降低人力成本,这些反哺直接体现在电力股的财报之上。
国家电网旗下的国电南瑞在2024年前三季度营收323.1亿元,同比增长12.97%;归母净利润44.73亿元,同比增长7.53%。其中营收增长为近三年同期新高。2021年至2023年,国电南瑞营收分别为424.1亿元、468.3亿元和515.7亿元,同比增长10.15%、10.42%和10.13%;归母净利润分别为56.42亿元、64.46亿元和71.84亿元,同比增长16.30%、14.24%和11.44%,连续亮眼的业绩表现让国电南瑞2024年全年股价涨幅17%,跑赢了大盘,不过进入2025年,国电南瑞股价至今跌幅约7%。
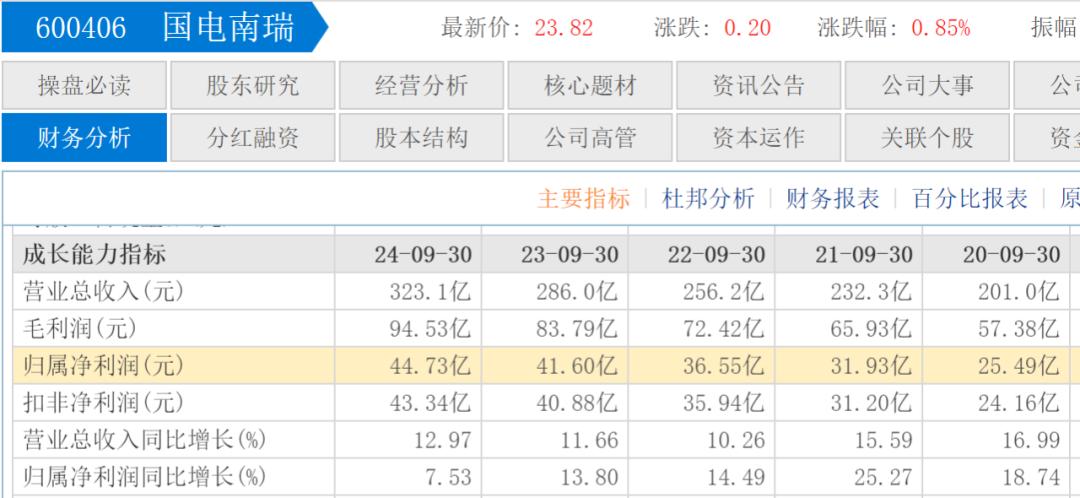
值得注意的是国电南瑞此前三年的净利润增幅均高于营收增幅,得以净利率的提升。2021年至2023年,国电南瑞的毛利率整体波动不大,分别为26.88%、27.04%和26.80%,但同期净利率逐年提升,分别为14.25%、14.74%和14.83%。净利率的稳步提升带来净利润的增幅高于营收增幅。
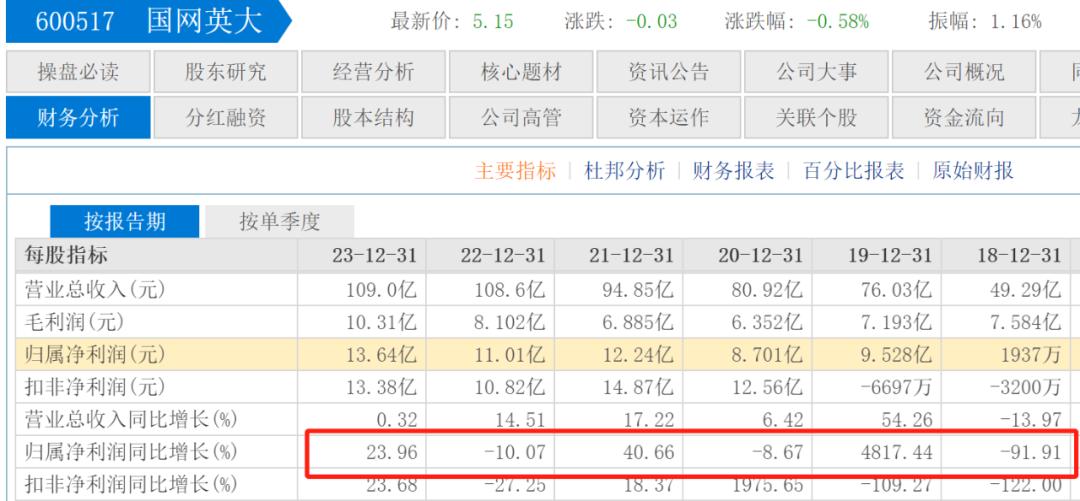
也不是每家电力股的业绩都如此出色,国网英大业绩就陷入波动之中。据财报显示,2021年至2023年,营收94.85亿元、108.6亿元和109亿元,同比增幅为17.22%、14.51%和0.32%,呈不断放缓趋势。而归母净利润更是波动较大,同期净利润分别为12.24亿元、11.01亿元和13.64亿元,同比增幅为40.66%、-10.07%和23.96%。往前6个完整财年,国网英大的净利润增幅均出现增长一年接着下滑一年的情况。
2024年前三季度国网英大营收76.94亿元,同比增长4.64%;净利润14.52亿元,同比增长26.26%。相比上一年同期1.85%的营收增幅,增幅明显提升,只是相比上一年39.78%的净利润增幅,增幅又出现明显下滑。国网英大整体利润提升较大,2024年股价涨幅也达18%,但进入2025年,股价回跌8%。
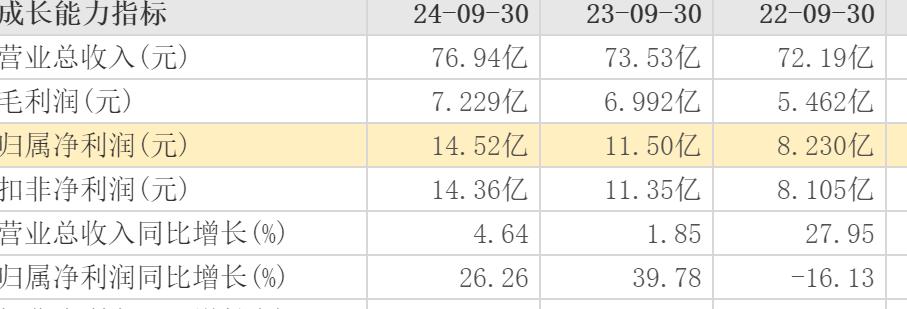
(国网英大2024年三季报)
从行业整体上看,这两年电力股整体业绩表现向好,AI算力在反哺电力系统上不只表现在业绩之上,智能电网优化能够通过分析历史数据和天气等因素,提升电力需求预测的准确性,帮助电网更好地平衡供需。在可再生能源整合上也较为出彩,通过风光预测,AI提高风能和太阳能的发电预测精度,帮助电网更好地管理这些间歇性能源。同时储能优化做到充放电最优化策略,提升可再生能源的利用率。在供给端、管理侧、网络安全以及设备管理与维护中,AI都有较大优势,在提升客户服务和使用体验上也具备一定的优势。
总之,AI在电力系统中的应用广泛,从优化电网运行到提升可再生能源利用率,再到增强网络安全和用户服务,AI正在推动电力系统向更智能、高效、可持续的方向发展。而如今中国AI算力的蓬勃发展同样离不开中国电力的支持,毕竟AI时代,电力为王已经是不争的事实,2024年中国发电量和装机量继续稳坐全球第一,保障了AI发展的电力需求,AI领域的发展也为电力企业的创新发展和降本增效带来了技术支持,两者相辅相成,形成共同发展的局面,在今年6500亿元资金的投资下,电力系统的发展或更值得期待。