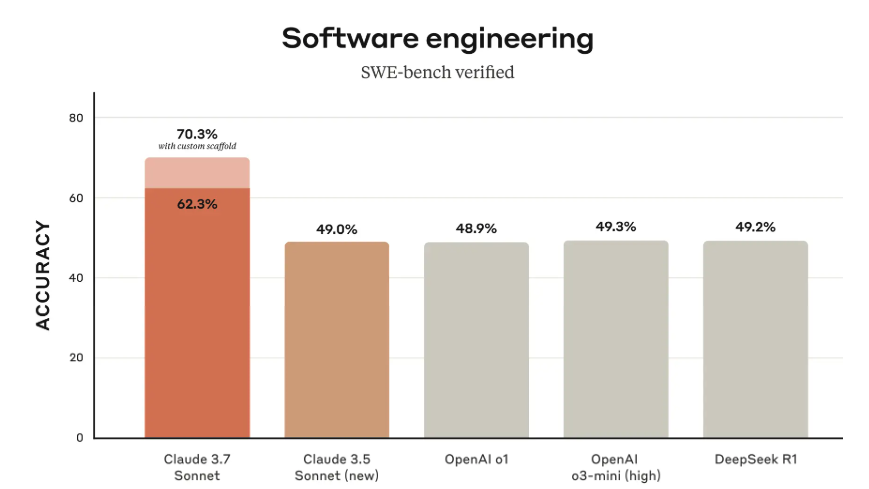
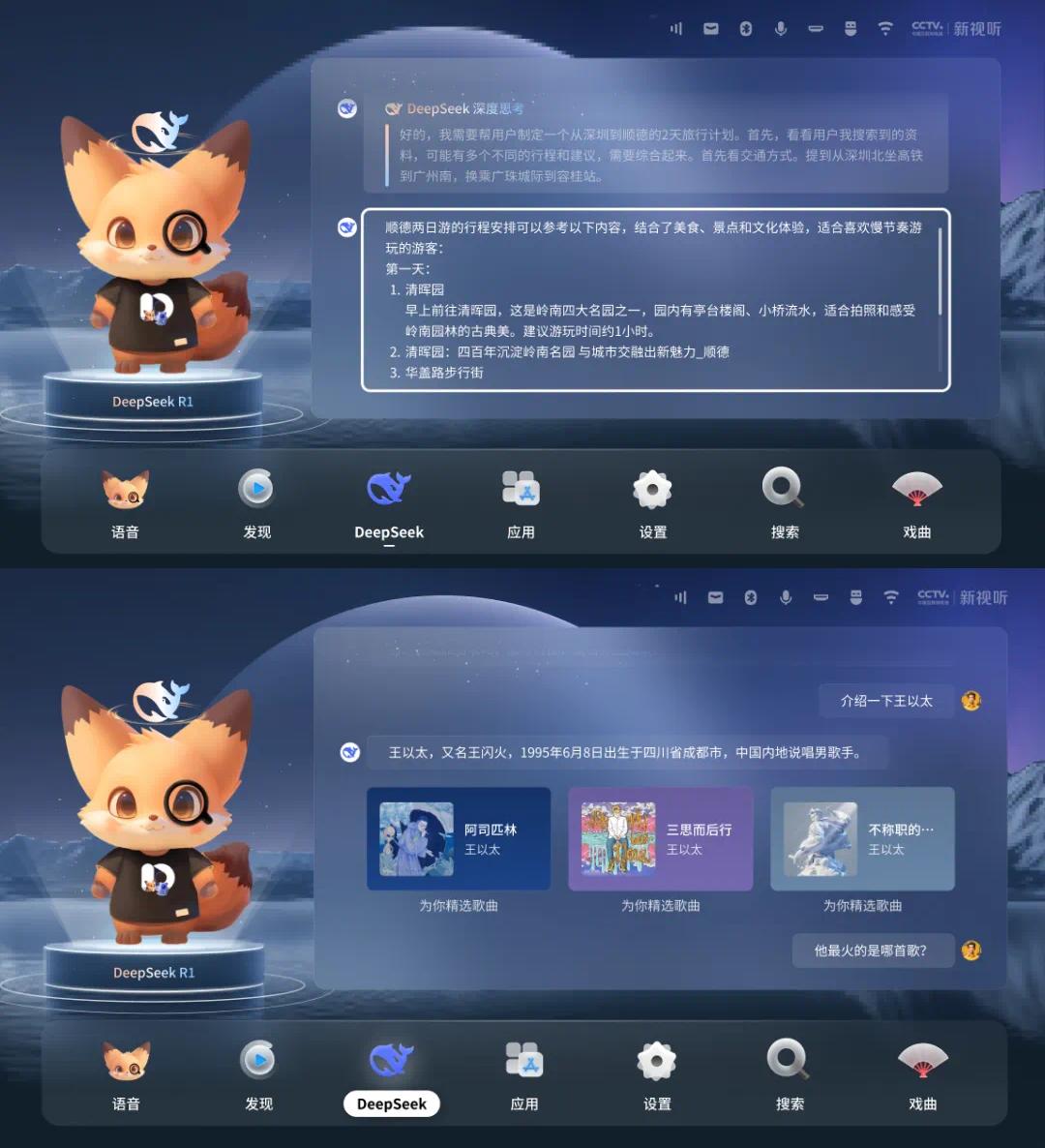
一夜之间,游戏产业要变天了!微软公布全球首个世界与人类行动模型,名为Muse,可秒生游戏画面,精准预测玩家操作。未来,游戏开发或将从数月压缩至几分钟,千亿美金游戏市场或被颠覆。
同一天,微软放出两个核弹,首个拓扑量子芯片,还有首个世界与人类行动模型。
AI离数秒生成游戏视频的未来,又近了一步。
今天,微软团队首次引入了「世界与人类行动模型」(WHAM),并冠以希腊艺术女神「缪斯」(Muse)之名。
它可以生成游戏视觉效果、控制器动作,甚至可以全都要。最新研究登上Nature期刊。

论文地址:https://www.nature.com/articles/s41586-025-08600-3
在相同的10帧(1秒)真实游戏玩法的条件下,Muse生成了行为和视觉多样性的样例。
同时,这也是首个基于Ninja Theory的多人对战游戏Bleeding Edge,超10亿张画面训练的GenAI模型。从单个V100集群,成功scaling到多达100个GPU上完成训练。
Muse AI强大核心在于,对3D游戏世界的深度理解。
它不仅仅是一个简单视频生成工具,而是能够精准模拟游戏中物理规则、玩家行为。
比如,当玩家按下手柄某个按键时,Muse AI可以预测游戏世界动态变化,并生成与之匹配的连贯画面。

传统上,游戏开发需要数月甚至数年,进行角色设计、动画制作和游戏测试。而如今,Muse能够将这一周期从几个月缩短至几分钟。
对于游戏开发者来说,它的出现无疑是一场革命,是颠覆千亿游戏产业革命的存在。
就连马斯克在AI游戏上押下重注,据称其创办AI游戏工作室即将要官宣。


AI重塑游戏开发,全球30亿玩家狂欢
Muse AI诞生之前,还有这么一段精彩的故事。
2022年12月,微软研究院游戏智能团队的负责人Katja Hofmann刚刚结束产假,回到工作岗位。
她忽然发现,在自己休假这段时间里,机器学习领域发生了翻天覆地的变化——
OpenAI发布ChatGPT,这一基于Transformer架构的生成模型,展示出令人惊叹的能力,尤其是在处理大量文本数据时。
这一突破,让Hofmann开始思考,生成式AI的崛起,对于AI与视频游戏的交叉领域意味着什么?

他们发现,尽管GenAI展现出巨大的潜力,但多项研究表明,其能力往往达不到创意人员的期望值。
特别是,在3D游戏开发这种高难度复杂领域,LLM的应用还面临着诸多的挑战。
众所周知,3D游戏开发是一个需要多样化创意技能的过程,会涉及到角色设计、场景构建、剧情编写、互动机制等多个方面。
在Hofmann看来,丰富且多样化的游戏玩法数据,为进一步创新提供了关键数据。
这种时间相关、多模态的数据能够探索日益复杂的任务,从而生成更高质量3D世界、与NPC互动和游戏机制。
更重要的是,游戏产业作为全球娱乐产业最大领域,已经覆盖了超30亿人口。
GenAI的出现,为世界游戏玩家们,甚至游戏工作室提供了一个绝佳的机会。
那么,微软团队是如何打造出Muse AI?
Xbox真人实战,超10亿张图像
微软的游戏智能团队,拥有非常不同的数据来源。
多年来,研究团队与Xbox游戏工作室的Ninja Theory(与游戏智能研究团队一样,位于英国剑桥)合作,收集2020年发布的Xbox游戏《Bleeding Edge》的游戏数据。
《Bleeding Edge》是一款4对4的在线游戏。经玩家同意EULA后,比赛会被记录下来。
研究团队与Ninja Theory的同事以及微软合规团队密切合作,确保数据的收集符合道德规范,并且仅用于研究目的。

Bleeding Edge部分游戏角色
Ninja Theory的技术总监Gavin Costello,见证了相关研究,感到非常高兴:
在黑客马拉松中,首次将AI集成到《Bleeding Edge》中,而这只是开始:此后,从构建行为更像人类玩家的AI智能体,再到世界和人类行为(WHAM)模型在人类指导下,能够构想出全新的《Bleeding Edge》玩法。
能见证这项技术的潜力,让人大开眼界。
Muse训练数据
当前的Muse模型是在Xbox游戏《Bleeding Edge》的人类游戏玩法数据(视觉和控制器操作)上训练的。
下图左显示的是训练当前模型的300×180像素分辨率。在超过10亿张图像和控制器操作上,Muse(使用WHAM-1.6B)已经进行了训练,相当于人类连续玩7年多游戏。
下图右是相关研究团队,一起体验《Bleeding Edge》游戏。

直到2022年底,游戏智能团队一直将《Bleeding Edge》视为类人导航(human-like navigation)实验平台,还没有真正利用手中大量的人类玩家数据。
在文本模型的启发下,研究团队开始思考:「如果我们使用基于transformer的模型来训练这些海量的游戏数据,我们能够取得什么样的成果?」
扩大模型训练
随着团队开始深入研究,面临的一个关键难题是如何扩大模型训练的规模。
最初,使用了一个V100集群,并成功验证了如何扩展到在多达100个GPU上进行训练。这为后续在H100上进行更大规模训练奠定了基础。在项目初期,做出了一些关键的设计决策,主要是关于如何充分利用大语言模型(LLM)社区的见解,包括如何有效地表示控制器操作和图像。
扩大训练规模努力的第一个成果是一个令人印象深刻的演示。
当时Game Intelligence的研究员Tim Pearce整理了一些训练初期与后期的对比示例。看着这些演示,就像看着模型学习一样。
这为后续展示这些模型中如何出现缩放法则奠定了基础。
Muse训练中的一致性
给模型的提示是:输入1秒的人类游戏玩法(视觉和控制器操作)和9秒的真实控制器操作。
在这种设定下,Muse如果能够生成与真实情况非常接近的视觉图像,那么它已经捕捉到了游戏动态。
随着训练的进行,观察到生成的视觉图像质量明显提高。
在早期训练(10k训练更新)中,看到了初步的成果,但质量迅速下降。
在100k训练更新后,模型在时间上保持一致,但尚未捕捉到游戏动态中相对不常见的场景,如飞行机制。
随着额外训练的进行,与真实情况的一致性继续提高。例如,在1M训练更新后,模型学懂了飞行机制。
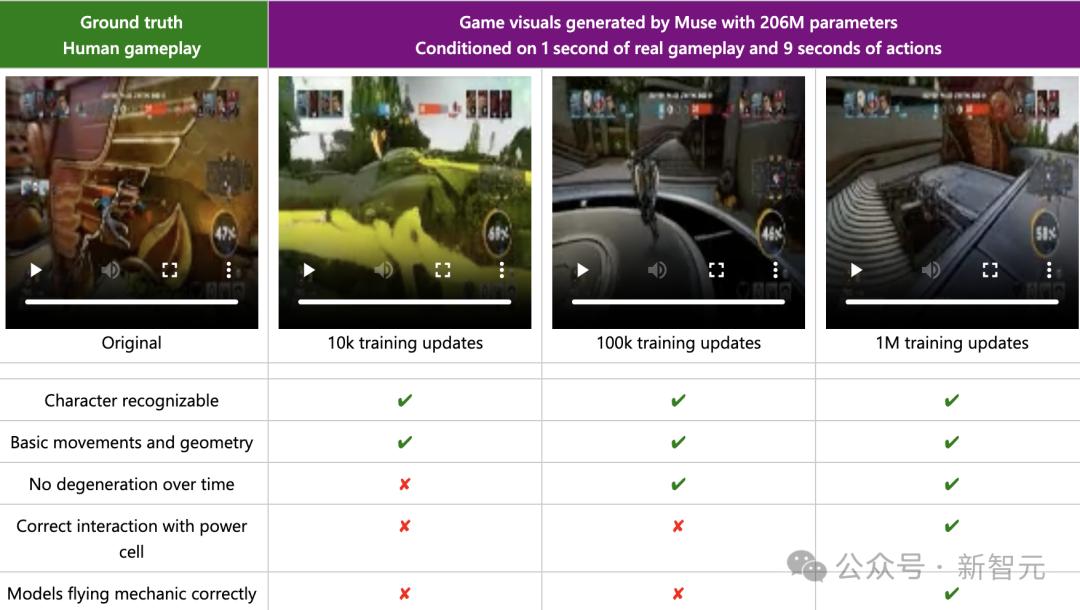
真实的人类游戏玩法(左)与Muse生成的视觉图像(使用WHAM-206M)的比较
跨学科合作:一开始就让用户参与
很早以前,研究团队就开始探索评估这类模型,比如下列3个项目:
研究实习生Gunshi Gupta和高级研究科学家Sergio Valcarcel Macua,推动了对线性探测学习到的表征的理解。
高级研究科学家Raluca Georgescu,负责探索了在线评估的方式。
研究实习生Tarun Gupta,主导了既有视觉特效又有动作的内容生成的研究。
但要系统地评估Muse,需要更广泛的见解。更重要的是,需要了解人们如何使用这些模型,以便知道如何评估它们。
这就是跨学科研究变得至关重要的地方。
研究团队已经与高级首席研究经理Cecily Morrison和Teachable AI Experiences团队合作了几个月,讨论了这项工作的各个方面。
在Cecily、设计研究员Linda Wen和首席研究软件工程师Martin Grayson推动下,团队还与游戏创作者合作,调查在创意实践中,游戏创作者希望如何使用GenAI。
Cecily说:「这是一个很好的机会,在早期阶段就联合起来,让模型满足创作者的需求,而不是试图改造已经开发的技术。」
关于如何处理这项工作,Linda提供了一些宝贵见解:
我们已经看到技术驱动的AI创新如何颠覆创意产业——通常让创作者措手不及,让许多人感到被排斥。
之所以从一开始就邀请游戏创作者,共同塑造这项技术,这就是原因。
北半球主导了AI创新。认识到这一点,我们还优先考虑招募来自代表性不足的背景和地区的游戏创作者。我们的目标是创造一个惠及所有人的技术——不仅仅是那些已经处于特权地位的人。
WHAM Demonstrator解锁新创意
现在,随着模型逐渐显现的能力和用户的反馈,是时候将所有部分整合在一起了。
在微软内部的黑客马拉松中,不同团队共同合作,探索Muse可以解锁的新交互范式和创意应用场景。
最终,开发了一个原型,命名为WHAM Demonstrator,它允许用户直接与模型进行交互。
Martin 说:「全球黑客马拉松是一个完美的机会,大家齐聚一堂,构建了了第一个工作原型。我们希望为WHAM模型开发一个界面,这样就能探索它的创意潜力,并开始测试从与游戏开发者的访谈中得到的想法和应用。」
为了与诸如Muse之类的AI模型进行互动,WHAM Demonstrator提供了与WHAM实例互动的视觉接口。
用户可以探索新玩法,并进行调整,例如使用游戏控制器来控制角色。 这些功能展示了 Muse 的能力如何在创作过程中支持迭代和调整,帮助用户不断优化和完善游戏体验。
模型架构与评估
使用WHAM演示器亲身体验Muse的能力,并从用户研究中获得见解,研究团队系统地确定了在使用像Muse这类生成模型时,游戏创作者所需的关键能力:一致性、多样性和持久性。
一致性:指的是模型生成游戏玩法时,能够尊重游戏的动态特性。例如,角色的移动与控制器操作一致,不会穿过墙壁,通常反映了游戏底层的物理特性。
多样性:指的是模型在给定相同的初始提示时,能够生成多种游戏玩法变体的能力。
持久性:指的是模型能够将用户修改(或「持久」)整合到生成的游戏玩法中的能力,例如将一个角色复制粘贴到游戏中。
模型架构设计
建模设计反映了识别出的模型能力,如下图所示。
一致性:一个顺序模型,能够准确捕捉游戏视觉和控制器操作之间依赖关系。
多样性:能够生成数据并保留视觉和控制器操作序列条件分布。
持久性:基于(修改过的)图像和/或控制器操作,通用条件化的预测模型得以实现。
在全部三个能力中,选择提供可扩展性的组件,这意味着模型应该从大量训练数据和计算资源中受益。
WHAM设计如图所示,它建立在transformer架构上,作为其序列预测骨干。
新方法的关键在于将数据框定为离散token序列。
为了将图像编码为令牌序列,使用VQGAN图像编码器。用于编码每张图像的令牌数量是一个关键的超参数,它在预测图像的质量、生成速度和上下文长度之间进行权衡。
对于Xbox控制器操作,尽管按钮天生是离散的,将左和右摇杆的x和y坐标离散化为11个桶。然后训练一个仅解码Transformer来预测交织的图像和控制器操作序列中的下一个token。
然后,该模型可以通过自回归采样下一个token来生成新序列。
还可以在生成过程中修改令牌,允许对图像和/或操作进行修改。也就是说控制器操作或直接编辑图像本身,可以控制(或提示)生成的能力,这评估持久性的先决条件。

WHAM架构概览
一致性
通过使用真实的游戏玩法和控制器动作来提示模型,并让模型生成游戏视觉效果来评估一致性。此处展示的视频是使用Muse(基于 WHAM-1.6B)生成的,展示了模型生成长达两分钟的一致游戏玩法序列的能力。
在论文中,还使用FVD(Fréchet Video Distance,视频生成社区中一个既定的指标)将生成的视觉效果与真实的视觉效果进行了比较。
多样性
在总共102,400个动作(1,024 条轨迹,每条轨迹100个动作)中,对10,000个人类和模型动作进行子采样,并计算它们之间的距离。
重复此过程十次,并绘制平均值 ± 1个标准差。越接近人与人之间的基线越好。均匀随机动作的距离为5.3。所有模型都通过训练得到改进,并且可以通过增加动作损失的权重来进一步改进。
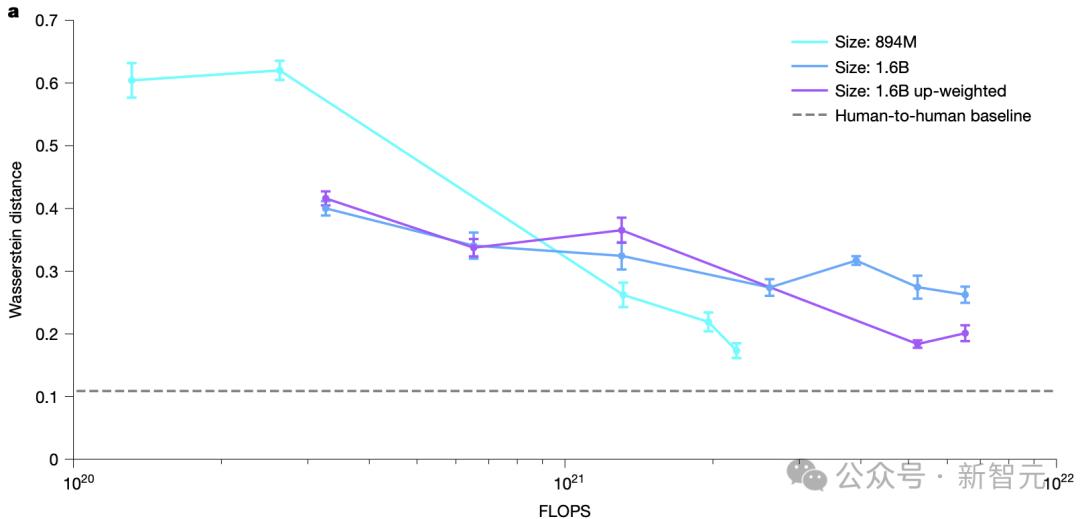
图a:三种WHAM变体的多样性,通过与人类动作的Wasserstein距离来衡量。
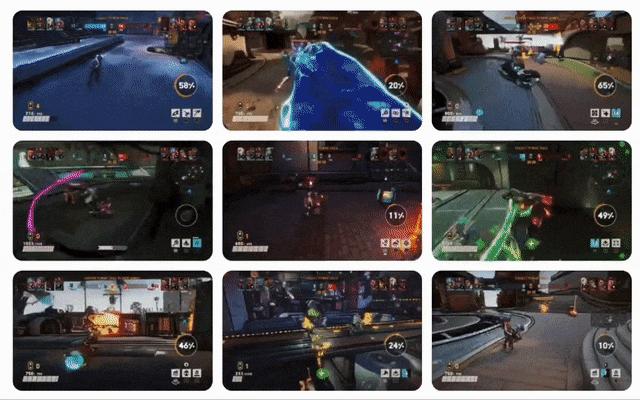
在下图b中,看到行为多样性(玩家角色在生成位置附近盘旋与直接前往 Jumppad)和视觉多样性(玩家角色安装的悬浮滑板具有不同的皮肤)的示例。

图b:使用相同起始上下文生成的1.6B WHAM的三个生成示例。
持久性
下列视频展示了Muse(基于WHAM-1.6B)如何保持修改的一些示例。
首先,取自原始游戏数据的一张视觉图像,然后将另一个角色的图像编辑到这张图像中。
生成的游戏序列展示了该角色是如何被融入到生成的游戏序列中的。
开源资源
与此同时,为了帮助其他研究人员,研究团队决定将开源 Muse 的权重、样本数据,并提供WHAM Demonstrator可执行文件——这是一个概念原型,提供了一个可视化界面,用于与 WHAM 模型进行交互,并支持多种方式的模型提示。

项目链接:https://huggingface.co/microsoft/wham
像Muse这样的模型,能够学习到的游戏世界的丰富结构,更重要的是,新研究还展示了如何通过研究洞察来支持生成性AI模型在创意领域的应用。
参考资料:
https://www.nature.com/articles/s41586-025-08600-3
来源:微信公众号“新智元”