AI搜索“老大哥”Perplexity,刚刚也推出了自家的Deep Research——
随便给个话题,就能生成有深度的研究报告。

先来划个重点:免费向所有人开放!
具体来说,非订阅用户每天最多可查询5次,Pro用户每天可查询500次。
然后啊,效果是酱紫的。
例如给出一个问题:
What should I know before the market opens?开市前我该知道些什么?
在Deep Research加持下的Perplexity先是会查找海量的资料:

接下来是推理过程,用Perplexity的话来说就是专家级别的分析:

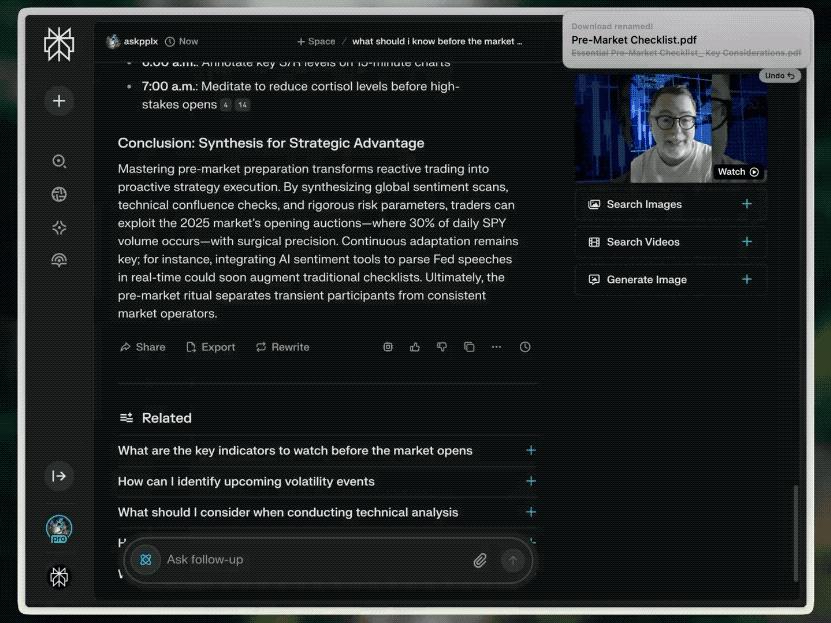
对原始材料进行充分评估之后,Perplexity就会将所有研究综合成一份清晰而全面的报告:

最后,你还可以把Perplexity写好的专业报告一键导出,格式包括PDF、Markdown和Perplexity Page:
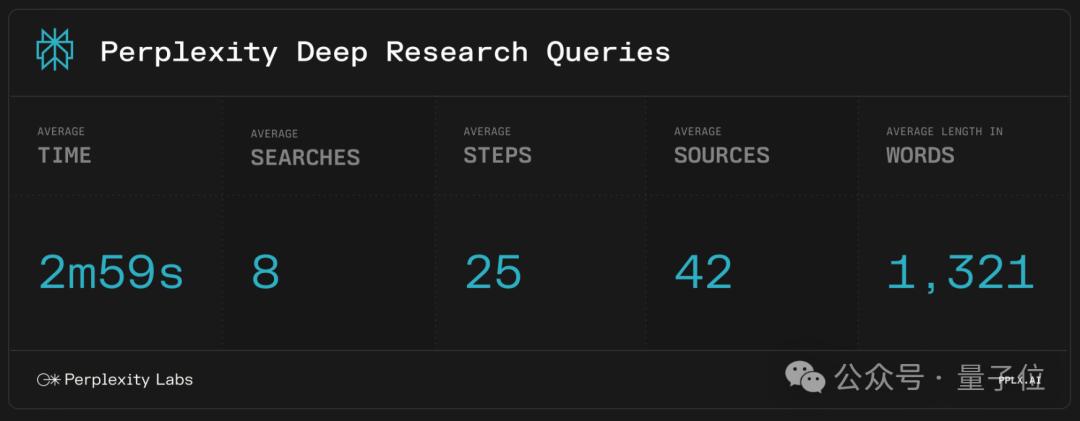
在性能方面,Perplexity官方也给出了他们的测试结果。
他们采用的基准,是最近考验AI推理能力大火的Humanity’s Last Exam(人类的最后考试),准确率达到了20.5%。
(注:“人类的最后考试”涵盖100多个科目、包含3000多个问题,涉及数学、科学、历史和文学等领域。)
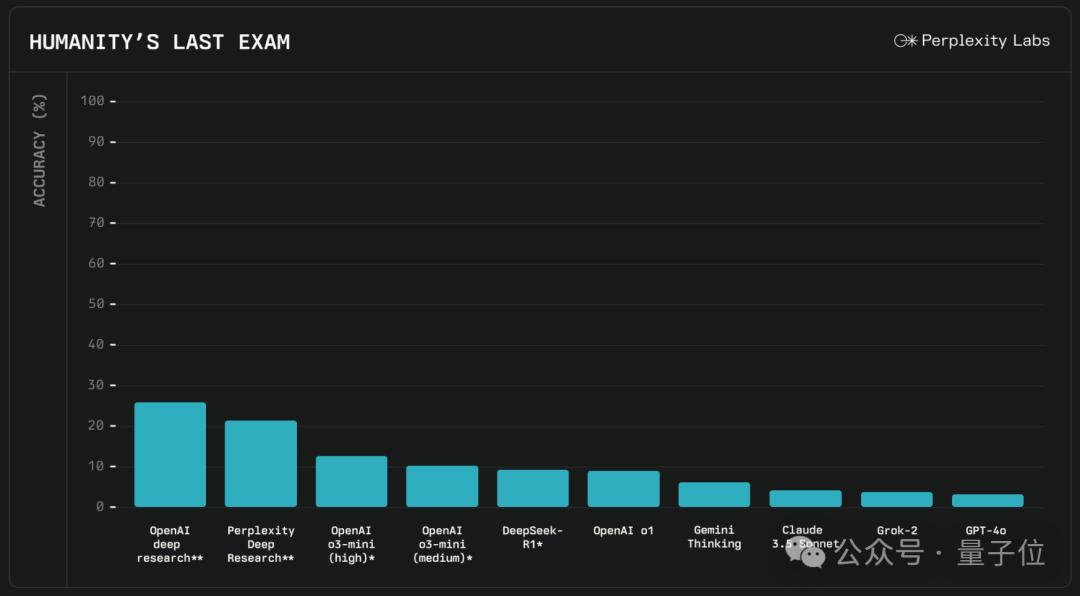
从成绩上来看,是优于Gemini Thinking、o3-mini、o1、DeepSeek-R1和其他许多主流模型。
在另一项SimpleQA(一个包含数千个测试事实性的问题库)的测试中,Perplexity Deep Research的表现更是明显远超领先模型,达到了93.9%的准确率。

更重要的一点是,Perplexity的Deep Research有够快——平均在3分钟内可以完成大多数研究任务。
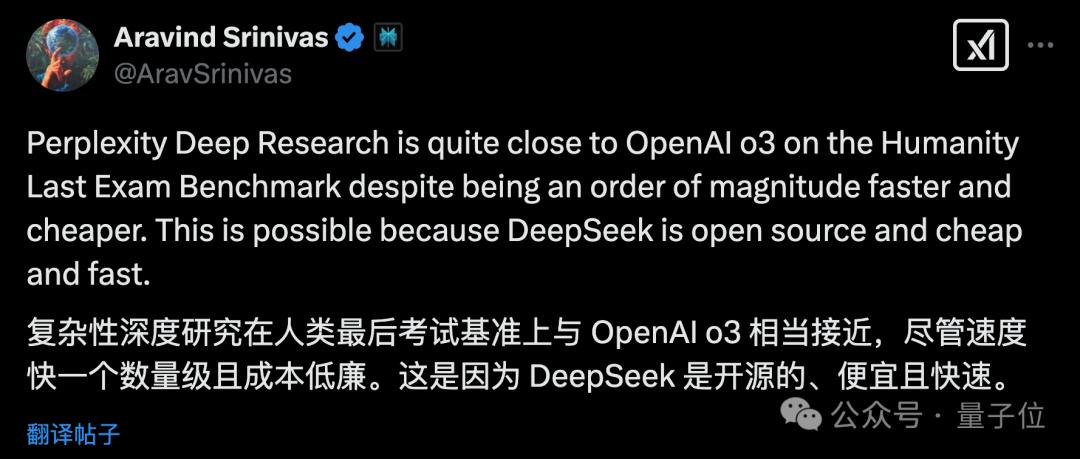
对此,Perplexity的CEO(Aravind Srinivas)公开致谢DeepSeek:
这是因为DeepSeek是开源的,又便宜又快。
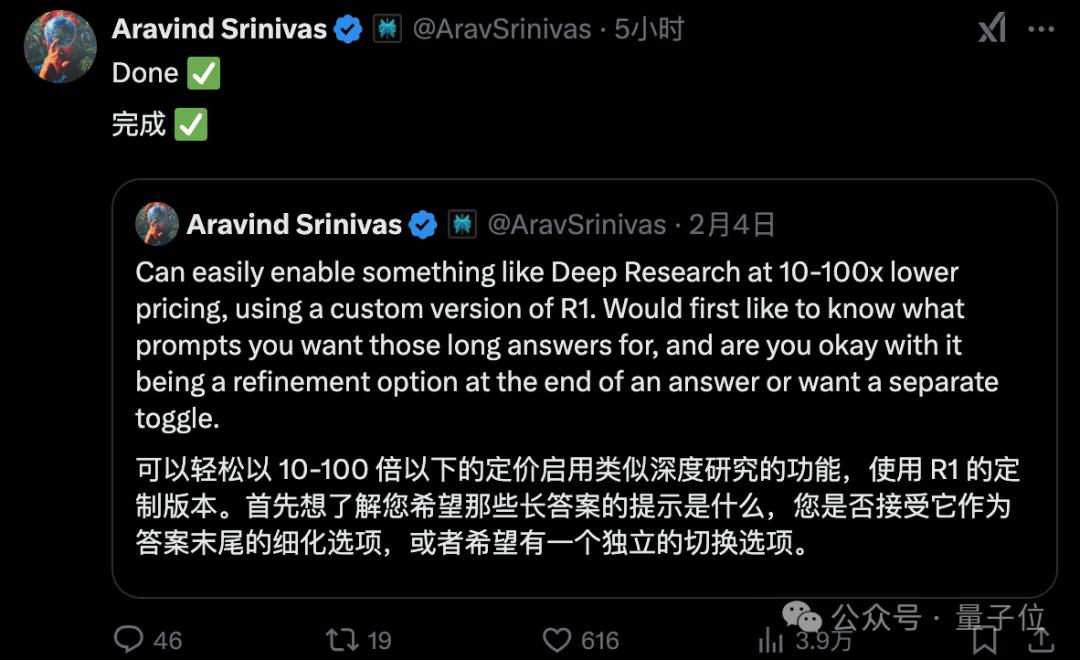
其实在10天前的一条推文中,Aravind Srinivas其实已经有所剧透:
在推文下方的评论中,我们也看到了不少关于DeepSeek的身影:

不得不说,DeepSeek的含金量还在上升。
实测Perplexity的Deep Research
Perplexity新功能的操作方式也是极其简单。
只需在搜索框下方的选项中pick一下Deep Research即可:
从官方展示的案例来看,Deep Research擅长在金融、市场营销和技术等领域的深度研究,并且在健康、产品研究和旅行计划等领域作为个人顾问同样有用。
例如在默认搜索和Deep Research下,同时问:
What’s the best strategy for advertising at the Super Bowl? Analyze the ROI of each major advertiser at the 2025 Super Bowl. Which brands were the biggest winners and losers? What ad techniques were most and least effective? If I wanted to advertise at the 2026 Super Bowl, what should I do to maximize success?在超级碗(Super Bowl)投放广告的最佳策略是什么?分析2025年超级碗上每个主要广告商的投资回报率(ROI)。哪些品牌是最大的赢家和输家?哪些广告技巧最有效和最无效?如果我想在2026年超级碗上投放广告,我该怎么做才能最大限度地取得成功?
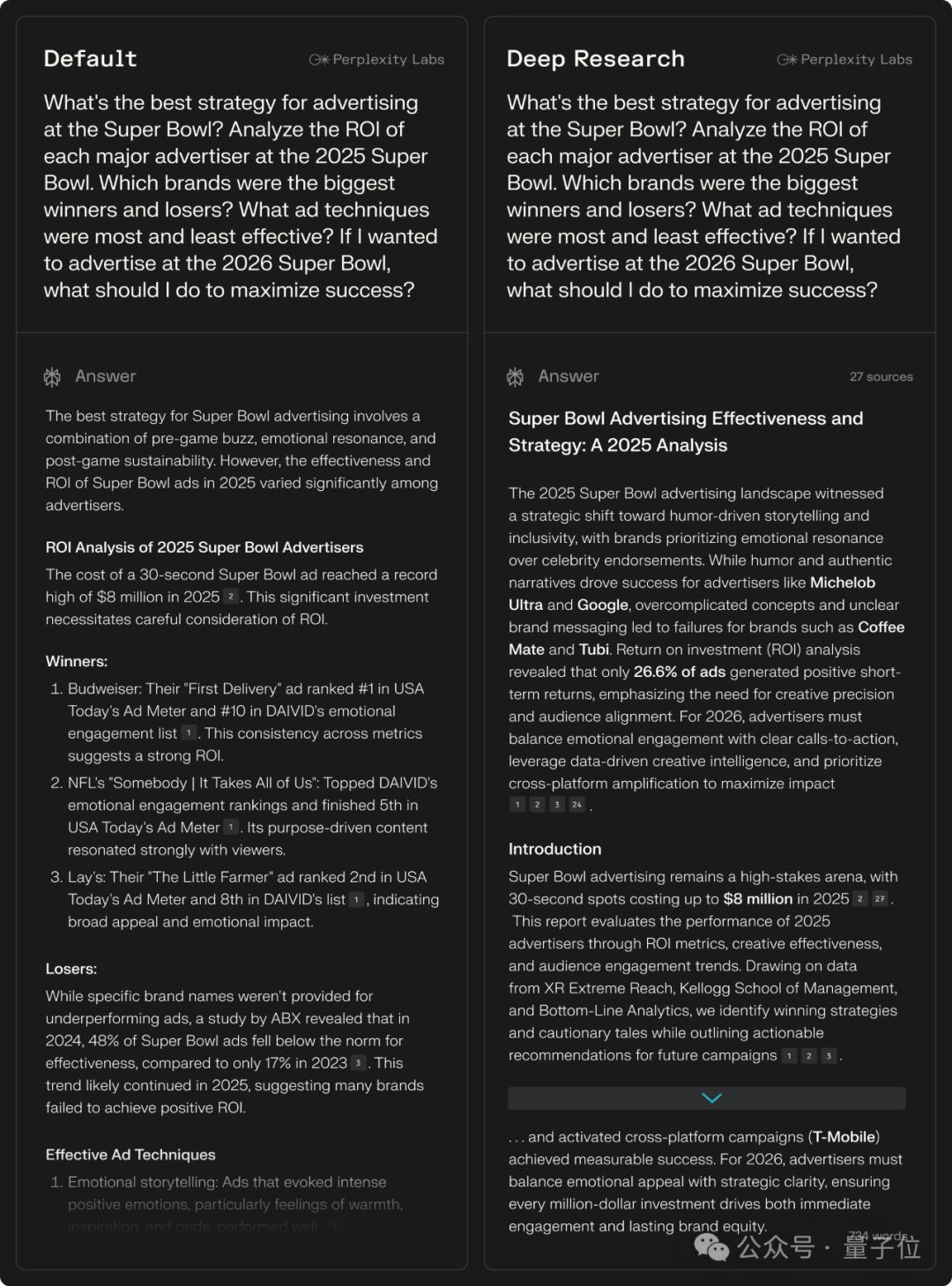
可以看到,Deep Research给出的答案更像是一个专业的报告。
先是以类似论文“摘要”的形式,把问题的核心亮点全部提炼、总结出来,然后再撰写并展开包括Introduction在内的更多内容。
同样的,让Deep Research完成撰写“黄仁勋传记”,从输出内容和格式来看,是更加清晰且一目了然:

现在,也有很多网友开始在网上po出自己实测的效果。
例如让Perplexity做下面这个任务:
compile a research report on how has retail industry changed in the last 3 years.编写一份关于过去3年零售业变化的研究报告。
然后这位网友还总结了一下Deep Research和普通AI搜索功能的区别:
普通搜索为简单的查询提供快速的、表面的信息。它适用于查找基本事实或获得简短的摘要。另一方面,Deep Research是为需要深入分析的复杂、多层次的查询而设计的。
正常的搜索通常会在几秒钟内产生结果。Deep Research是一个更耗时的过程,需要5到30分钟才能完成。
但,好多“Deep Research”啊
除了效果之外,对于Perplexity发布的Deep Research,网友们还有另外一个热议的焦点——名字。
例如有网友就直接提出了自己的困惑:
Deep Research是你们能想到的唯一的名字了吗?


其实这也不怪网友们提出这样的质疑。
因为……现在有太多叫Deep Research的产品了……
2024年12月,谷歌发布Deep Research
2025年2月,OpenAI发布Deep Research
2025年2月,Perplexity发布Deep Research

AI的问题,我们就让AI来回答。


Perplexity在回答中总结出了一个表格:

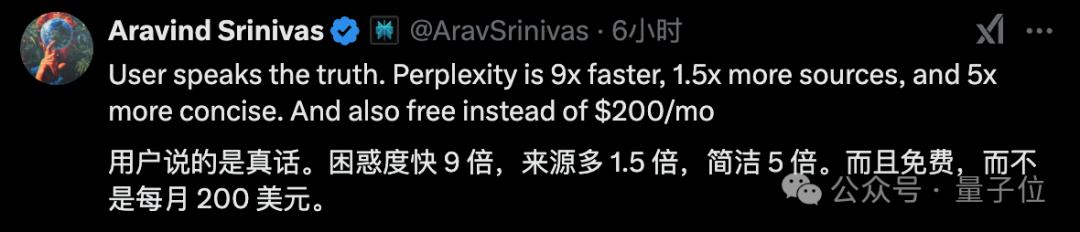
CEO对此也给出了自己的答案,一言蔽之,就是“快好省”,不过他顺便还阴阳了一波OpenAI:
我们每月不用200美元。
最后,CEO还预告了一则消息,下周Perplexity还有一个很cool的东西要发布。