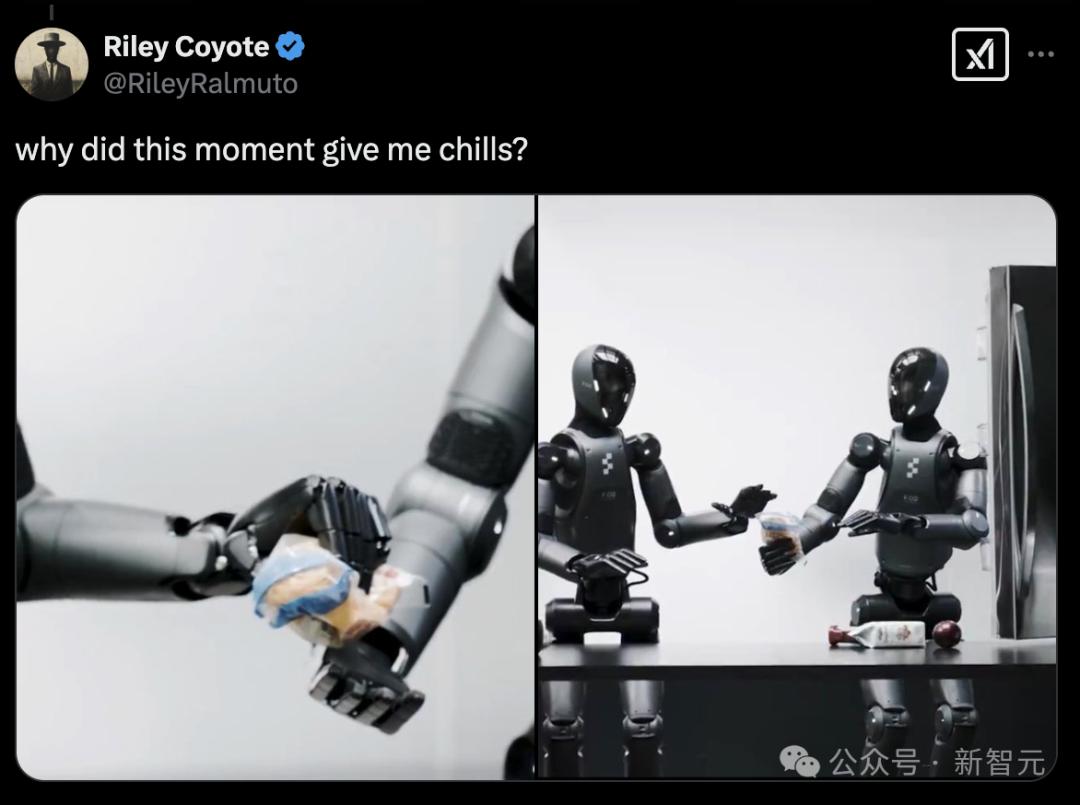
刚刚发布48小时,Grok 3的第一批“受害人”就出现了。
有用户才花40美元订阅了X的Premium+服务,想要畅玩xAI的最新一代大模型Grok 3,结果一看马斯克在社交媒体X上的豪言,心凉了半截。
“短期内,Grok 3将免费提供给所有人!”马斯克如是说。而xAI的官方X账号则放出豪言,免费开放,“直到服务器崩溃”。
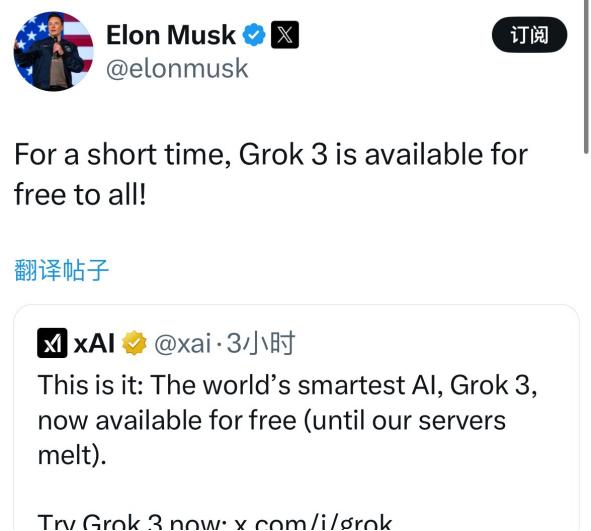
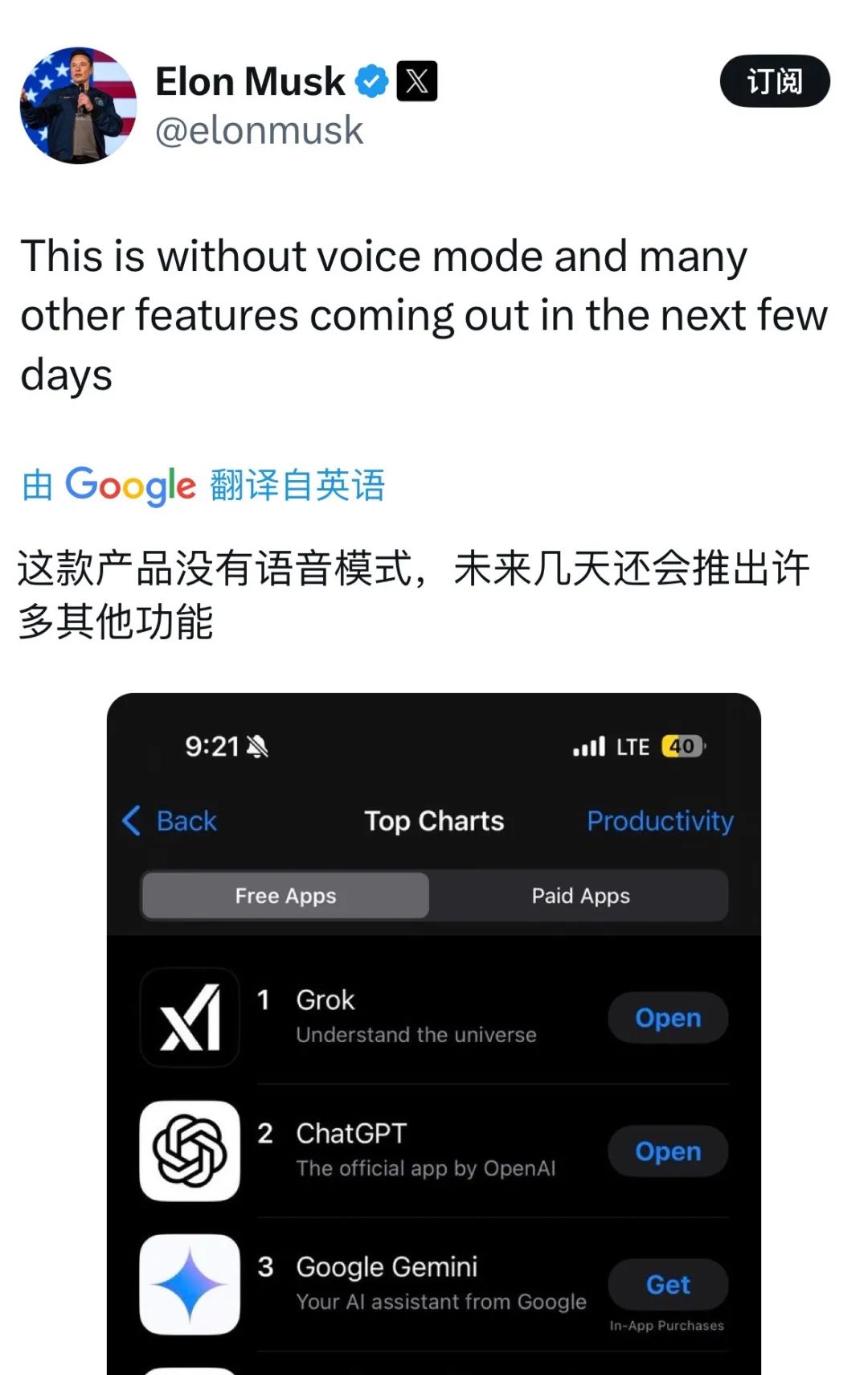
几个小时之后,马斯克又快乐截图苹果应用商店生产力工具榜单,Grok的独立应用登顶免费榜,这也是其首次超越ChatGPT。马斯克还强调,这还是语音模式还没推出的情况下。
马斯克大手一挥当好人,本来就是免费用户的有福了,为信仰充值Premium+的用户成了大冤种。
“兄弟,你是说我白白升了个级?”用户在相关消息的评论区无奈地说,还加上了两个小丑emoji,谁是小丑咱都不好意思点名。
更别提“每月40美元”也是在发布会之后涨价的结果,要不是Grok 3发布,X平台美国区Premium+的订阅费用仅为22美元。
Grok 3本就被视为马斯克针对OpenAI和DeepSeek的反击之作,尤其是推理模型Grok Reasoning更是把马斯克的心思展露无遗。
如今的免费一跃,也是xAI进一步在和两个竞争对手靠近。DeepSeek压根还没有面向普通用户推出付费计划,而OpenAI也在DeepSeek大火之后,将推理模型o3-mini下放给了免费用户。
只是咱们看齐归看齐,免费归免费,也不能这么突然、不顾付费用户死活吧?
A
Grok 3发布后的48小时,可真够乱的。
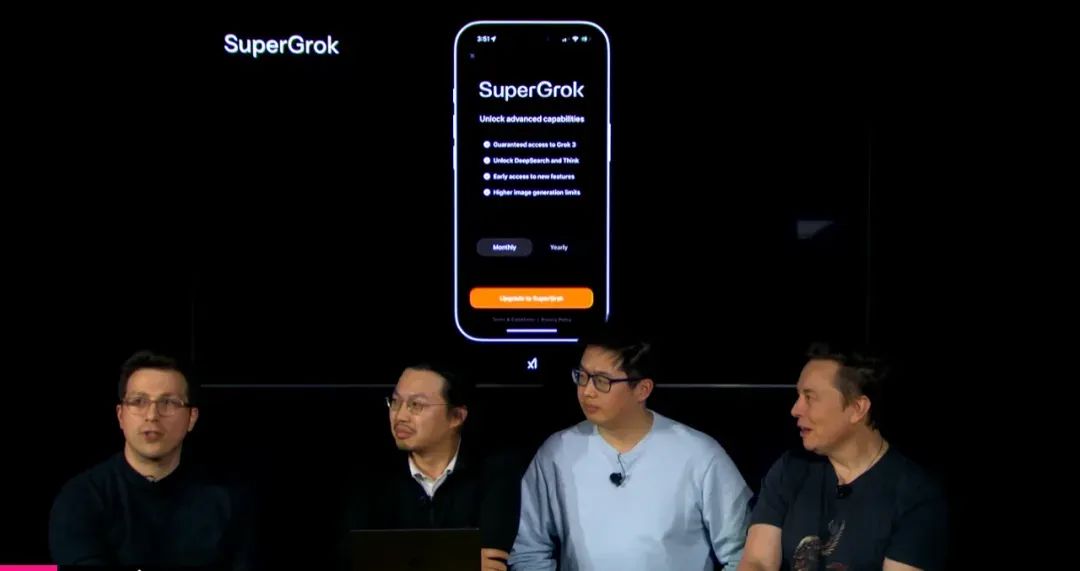
Grok 3的发布会在北京时间2月18日上午12点播出,彼时马斯克表示,试用的最低门槛是X的Premium+用户,每月订阅费22美元(美国区价格,下同)。此外,用户还可以在独立于X平台的Grok应用内,付费开通单独的SuperGrok服务。
SuperGrok是这次xAI才推出的新订阅计划,费用据报道会在每月40美元的水平。
然而,到了昨天上午,也就是Grok 3发布不到24小时的时候,人们惊讶地发现:马斯克偷偷给X平台的Premium+涨了个价?

前情提要:马斯克收购推特之后,将平台改名为X,并推出了订阅服务。X的订阅服务分为三个层级,分别是X Basic、X Premium、X Premium+(标准杯、大杯、超大杯)。在xAI成立后,马斯克进一步将大模型Grok也接入到X的订阅服务当中,作为尊贵订阅用户的一项特权功能。
当然,接入大模型,X的订阅服务也开始变贵。去年12月,X Premium+已经从16美元涨价至22美元。
而Grok 3发布之后,这个价格突然就从22美元进一步涨到了40美元。美国之外的其他市场也同步涨价,如英国从每月17英镑涨至35英镑;法国、德国等欧洲国家从每月21欧元上涨至38欧元。
虽然没有明说,但用户普遍认为这是在为Grok 3付费,毕竟其他两档计划的订阅费用不变,因此形成了3美元、8美元,突然跃升到40美元的奇怪格局,两档订阅之间的跨越过大。
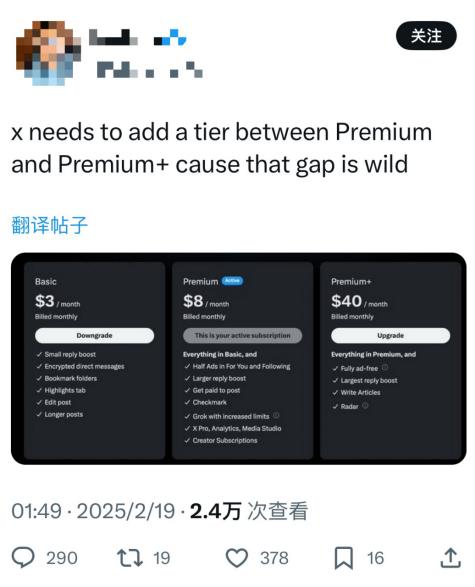
一天前还说Grok 3首先让Premium +用户享受上,马斯克甚至在发布会上鼓励大家感兴趣的话去开通订阅服务。结果一转眼价格几乎翻倍?就挺突然的,也挺不讲武德的。
而且,Grok应用中购买SuperGrok的话,每月50美元或者每年350美元,价格也比之前外界预估的要贵不少。
而且,升级到Premium+的用户发现,Grok 3确实可以用上了,但是限制的条数给得也太少了:
最让人崩溃的是,又过了一天,也就是北京时间2月20日上午十点半,xAI的X官方账号突然宣布:“全世界最聪明的AI,Grok 3,现在免费(直到我们的服务器崩溃)”。
而马斯克也转发了这条消息:“短期内,Grok 3全面免费!”
果不其然,刚刚付费(花40美元)升级到X Premium+的用户emo了。
之前还在X上和人辩论称有Grok 3的Premium+绝对值22美元一个月的价格,结果转眼看到涨价消息,也赶紧撇清自己:“对Grok我已经没有什么好话讲了。”
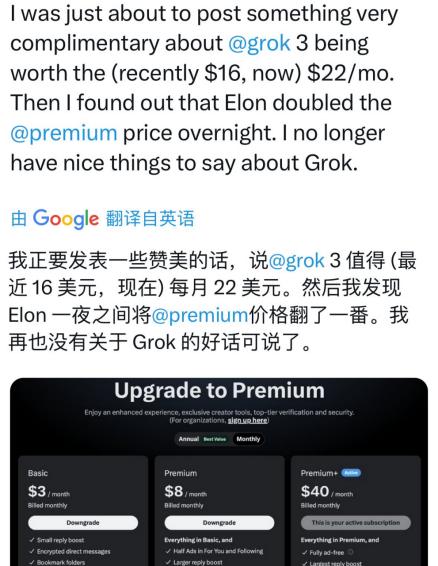
甚至有人引用了一年前马斯克的帖子,来表达对他破坏承诺的不满。在那条帖子中,马斯克承诺今后所有订阅超过5000人的X用户都将自动获得Premium+的权益。
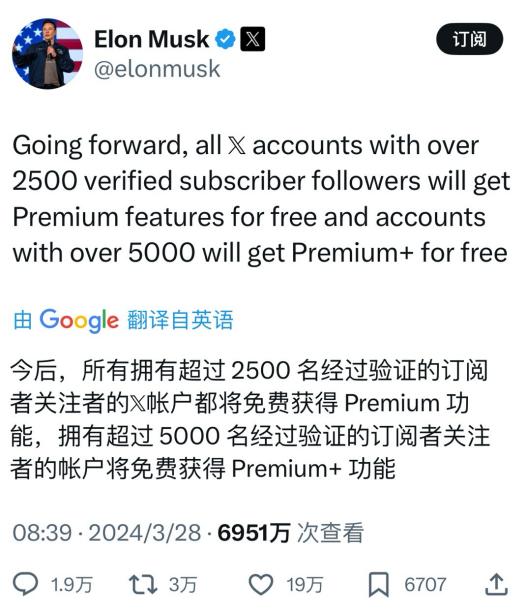
信谁能得永生咱不知道,但信马斯克很有可能被背刺。
B
虽然看起来马斯克发布了“全世界最聪明的AI”,而且还豪气地将之免费,但这背后反而暴露了些许焦虑。
免费的决策很有可能是没有经过深思熟虑的。
如今场面依旧十分混乱:
第一,经过用户不断在X上互相勾兑(交头接耳),才终于搞明白,Grok 3被声称免费开放了,但是免费用户似乎获得的是Grok 3的beta版本;Premium+用户可以用推理模型,有“深度搜索(DeepSearch)”和“推理(Reasoning)”,SuperGrok则有更多功能和无限的图像生成权限。
第二,免费用户每小时请求的数量十分有限。官方没有给出确切数字,有用户反馈大概是每小时请求5次的限额。而X的Premium+和Grok的SuperGrok用户,据说是有更多限额,每日请求次数更多,但具体多少,没有准话。
第三,Premium+涨价到40美元,但订阅费用似乎飘忽不定。国外科技媒体TechChurch测试发现,注册时显示39.83美元/月、477.95美元/年,最终结账页面却显示395美元/年。
如果一个用户对Grok3十分感兴趣,要搞清楚究竟是免费的就够用,还是要付费、付费的话又是哪一种方案最适合自己,又最终需要付多少钱,需要自己好好做一番功课。
相比而言,OpenAI的ChatGPT推出两年多了,只有三种方案,即免费、每月20美元的Plus和每月300美元的Pro;而谷歌把Gemini Advanced放在了谷歌的订阅“大礼包”之中,即每月20美元的Google One AI Premium。
各个订阅层之间的区别、定价,急需马斯克归置归置。
C
突然免费,可能也和48小时内用户对Grok3的反馈有关。面对DeepSeek的横空出世和OpenAI的快速跟进,马斯克端上Grok3,并不断强调这是“地球上最聪明的AI”。
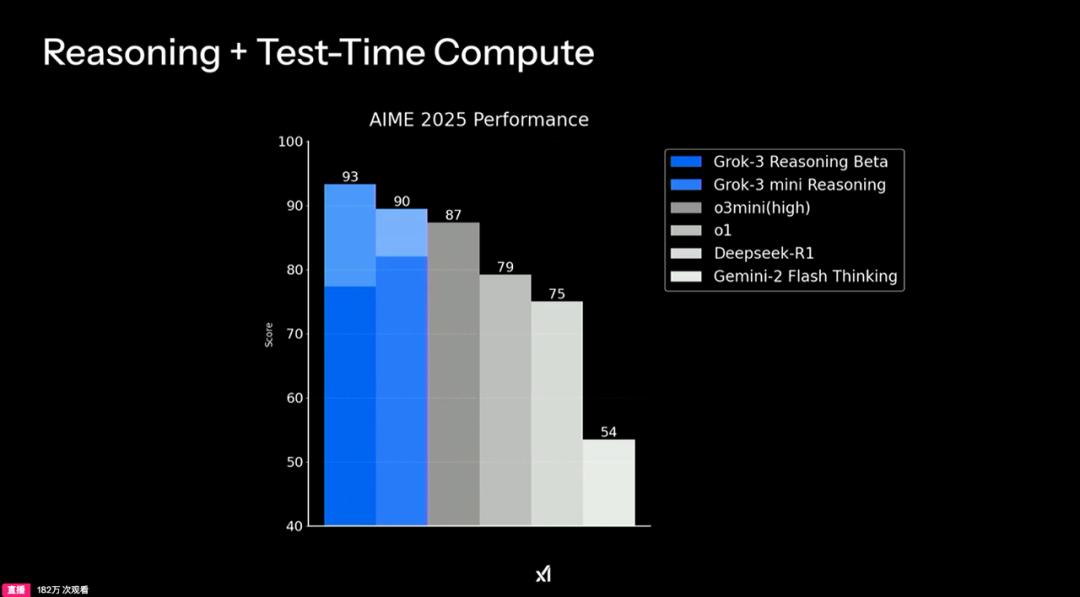
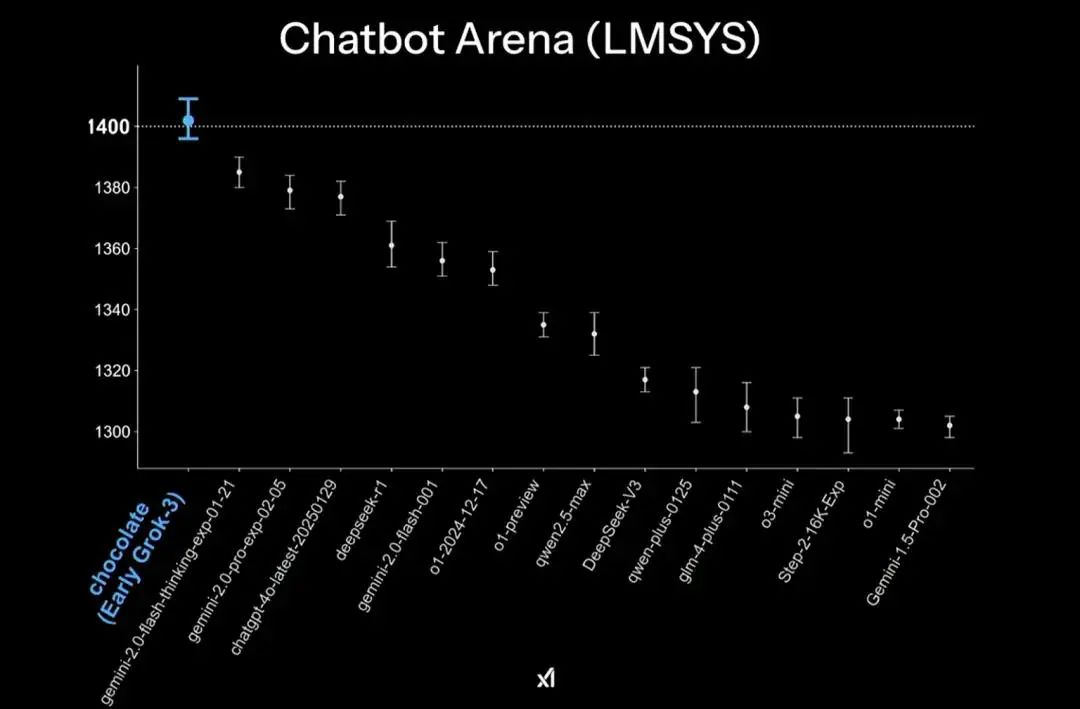
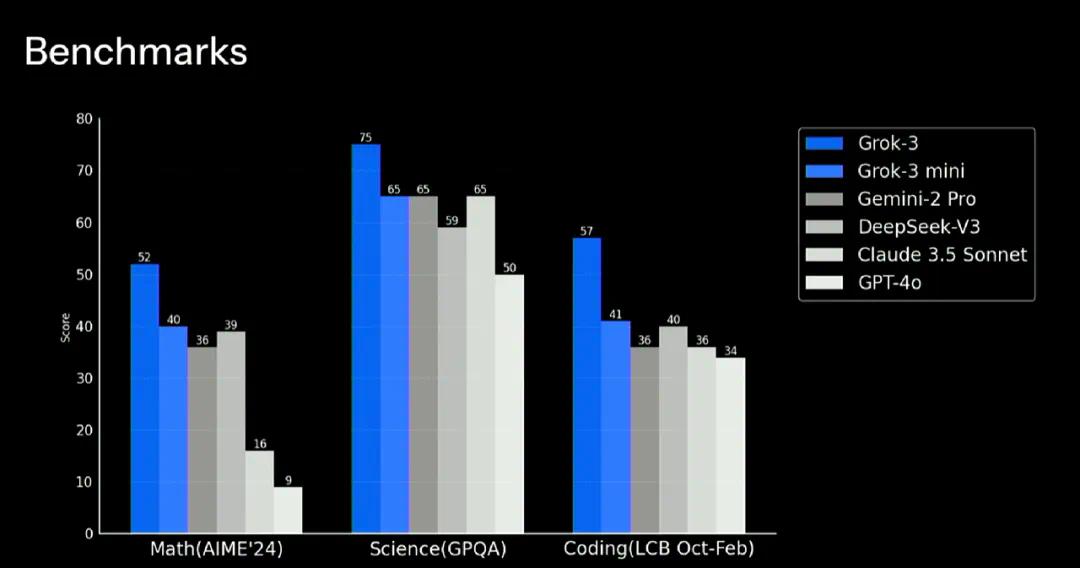
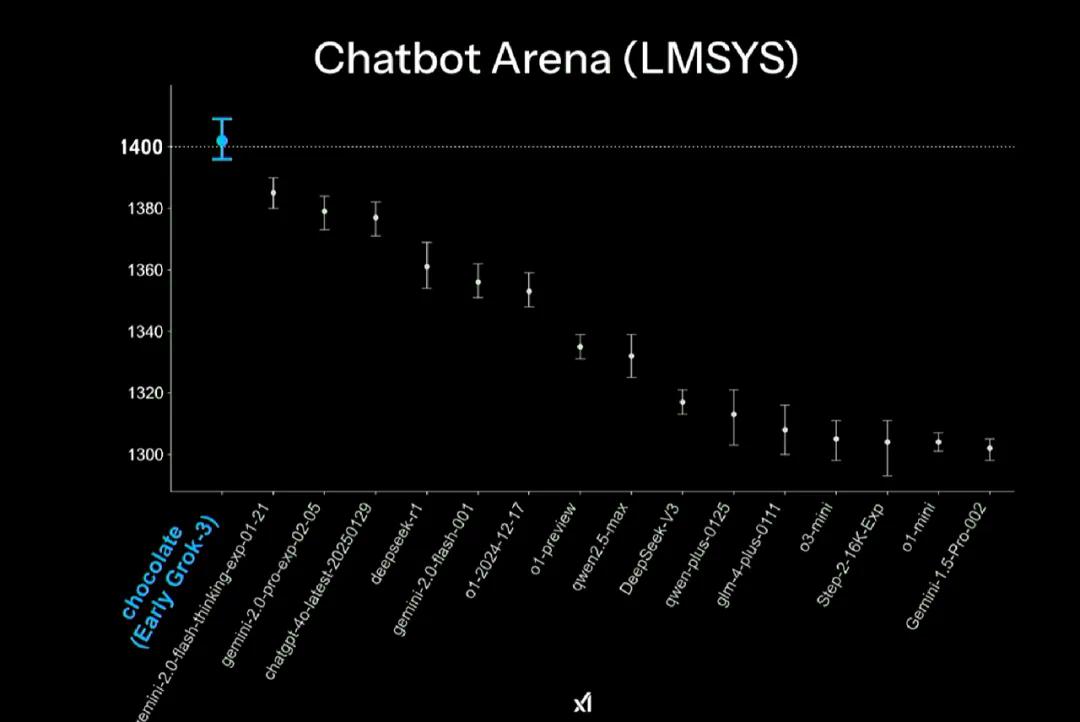
从xAI放出的Grok3在各种基准测试中的成绩,不难看出其实力的确过硬。但能否担得上“地表最强”,还要打一个问号。
毕竟傲娇如马斯克,都不断强调现在只是测试阶段,还呼吁大家务必反馈一切使用中遇到的问题。并且,马斯克给出了一些承诺,称语音模式等在路上,需要大概一周的时间和大家见面。
Grok3发布之后,各路测试接踵而至,但并未见到Grok3在各个方面碾压同行。至少比起两年前ChatGPT发布或今年DeepSeek走红所引起的轰动相比,Grok3可以说雷声很大,但雨点有那么一点点小了。
在xAI官方账号宣布Grok3免费的消息下,有很多评论都在表达对Grok3的失望,甚至是排着队接连出现,诉说自己提了多么简单的请求,而Grok3又是怎样地没有成功应答。

到最后,Grok3最出圈的依然是剑走偏锋的“没底线”。
主打“反觉醒”的Grok向来不会像竞争对手一样浑身都是敏感点、动不动就拒绝回答问题,不管是生成名人图片,还是回答敏感问题,抑或是“搞颜色”,Grok都很“大胆”。(而且生成裸体图片、讨论冒犯性话题等的安全栏已经被火速提高了,Grok3当下已经没有刚发布的时候那么狂野)。

在不远处,竞争对手也要更新模型了,如Anthropic很有可能在本周发布Claude 4。
而马斯克的Grok和“世界最聪明的AI”之间,大概不止一句“免费”和几张裸体照片的距离。
来源:微信公众号“直面派”