要知道,中国对于AI的热情可是全世界第一。任何有关AI的消息放出来,咱们都是最兴奋的,反倒是欧美人非常淡定。
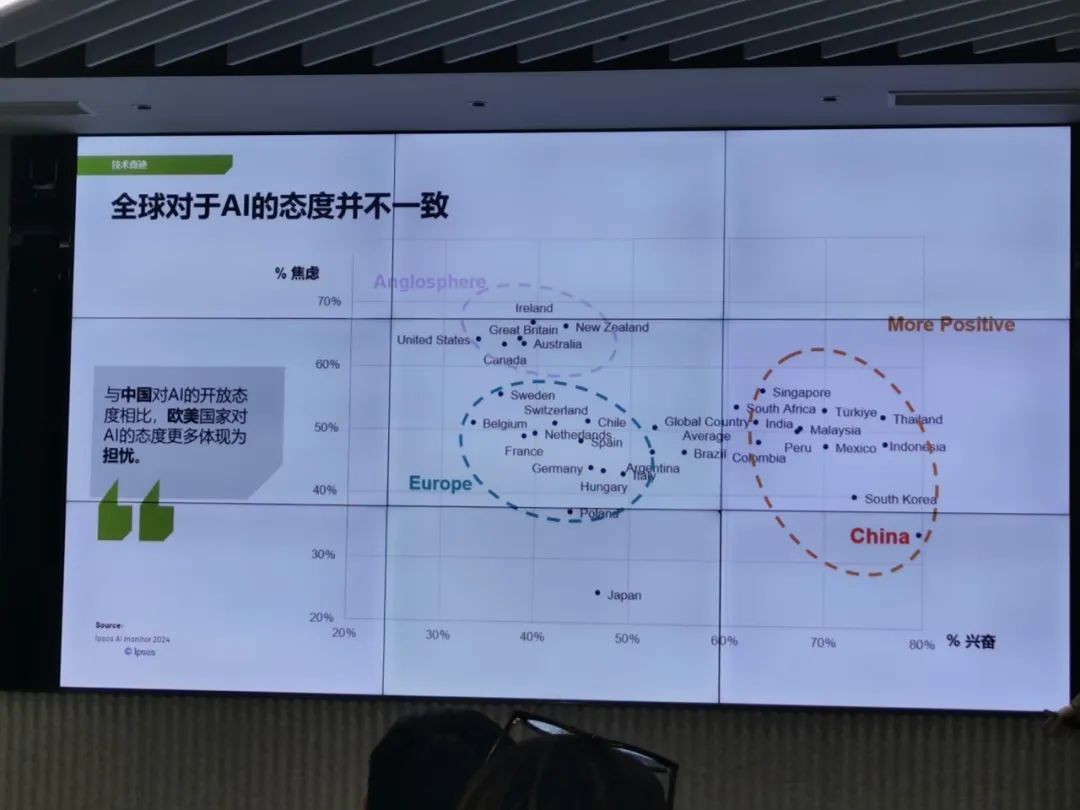
来源:益普索线下闭门会议
从生产端看,互联网平台接入AI搜索能力,早已不是什么稀奇的事情。
作为搜索领域的一哥,百度早早就接入了AI能力。2024年,在其7亿APP日活中,AI功能的渗透率已经超过了70%。
字节推出了“抖音搜索APP”和“豆包”,都具备强大的AI搜索能力,后者更是以千万日活常年霸榜国内AI产品No.1(前几天刚刚被deepseek反超)。
腾讯推出了元宝app,搭载了自研的混元大模型,是国内首个能够直接基于公众号、视频号内容进行AI搜索的工具。
小红书推出了“点点app”,基于自身内容专门构建了“生活灵感和攻略”的AI搜索能力
KIMI、天工、秘塔等独立AI产品,比互联网大厂更早地启用了AI搜索功能。
但在应用端,大家似乎把热情都用到了股市上,感觉股民们探讨AI的次数,有可能比公司CEO更多。

就在这几天,微信开始灰度测试接入DeepSeek-R1模型,提供“深度思考”服务,用户可通过微信对话框顶部的“AI搜索”入口免费使用该功能,整合了微信公众号、视频号等腾讯生态内容及全网优质信息源。
此番社媒巨头和大模型天花板的强强联合,在我们看来,很有可能诞生全新的商机。尤其是对于品牌做营销来说,一个新的场景和机遇正在孵化中。
为何会有新商机?
表面上看答案很简单:微信13.82亿MAU体量优势是任何一家公司都不具备的。相对应地,微信搜索功能的月活基本上是中国最多的,甚至超过了百度移动端,这代表了巨大的流量机会,大家都对一座隐藏的矿山充满了遐想。

但矛盾点在于,大家并不知道矿山里装的是什么:从2024年的情况来看,微信搜一搜的日均搜索次数又非常少,说明使用频次很低,这些流量能产生多少商业价值其实很难判断。

因为在我们的常规认知中,微信的心智从来都不是搜索,即使用户量再大,没有后链路的行动也白搭。

(数据来源:小红书@名道)
企业非常担心开采这座矿山,拿到的不是“金子”,而是低粘性、不精准的“铜铁”。至少从目前微信的广告收入来看,搜索占比还不高。
但是,这种情况正在发生改变。
首先看短期。我们在2024年Q3的用户调研显示:微信搜索是公众号内容的TOP1入口,同时也是视频号内容的TOP2入口。同时,用户的收入阶层越高、消费能力越强,通过搜索进入公众号内容的占比就越高。

对比抖音来看,其TOP1入口是“直接打开刷视频”,而TOP2是“APP消息推送召回”;而小红书的“直接打开刷内容”和“搜索”几乎是并列TOP1。
从内容消费的角度来说,微信的用户心智正在发生巨大的变化,更贴近小红书和百度,而不是抖音。根据微信公开课2023年的数据,微信搜索对于小程序新增日活用户的贡献占比、对于公众号新增粉丝的贡献占比分别高达20%和27%。[1]
腾讯2024年Q3的财报显示,得益于大模型能力提升了用户体验,微信搜索带来的广告营收同比翻倍增长。

其次看长期。越是具备复合功能的APP,才能在大浪淘沙中胜出,真正具备“生态”能力的平台,才是AI的主流入口。
比尔盖茨曾经表示:整个软件市场的格局都会改变。以后会需要多少应用程序呢?现在我们看到的是,每个人都在往自己的应用里加 AI,然后说:“看,我加了AI功能,所以得多收点钱。” 但是实际上呢,你需要的应用数量其实应该大大减少。[2]
由此我们推断:在用户行为发生变化的情况下,微信搜索的“含金量”会持续上升,直接联动了品牌在微信生态内的内容营销,促进私域资产的沉淀,甚至有可能导向直播间、小程序等交易场景。
这对于企业营销获客、品牌建设来说的确是值得关注 – 如果在AI的加持下,能够提升用户体验并促进更多的活跃度,自然是新的增量。
那么,增量具体会出现在什么地方?
商机1:
企业官网和社媒账号有机会获得更多自然流量
不仅仅是微信,随着“AI+搜索”的发展,整个市场都会为企业营销创造免费、长尾流量的机会,底层逻辑与搜索引擎优化(SEO)有点类似。
从运作原理来说:无论什么AI工具,在用户提问后,除了给出总结性内容之外,还会给出信息来源的链接作为注释。与传统搜索引擎一样,大多数情况下,用户就会选择性点击这些链接,进一步了解详细信息。
如果企业提供的内容能够被AI算法收录并提供给用户作为答案的一部分,那么企业就有机会从AI搜索入口收获额外的流量。
这主要体现在企业官网、电商页面、社媒账号的流量增长上。我们先对标国外成熟市场看趋势,再参照微信的功能思考机会点:
一项大范围的网站流量研究显示,有63%的网站至少收到过一次AI搜索引擎(如chatgpt、bing、gemini等)推荐来的访客。也就是说,任何公开的网站都有63%的机会从AI搜索引擎获得额外的流量。其中,98%AI流量来自三巨头身上:ChatGPT、Perplexity 和 Gemini。[3]
放到国内,对于很多品类来说微信公众号/小程序几乎就成为了“企业官网”的代名词[4] 。 企业的Own media内容,有了更大的概率被精准客户发现,从而产生兴趣。作为唯一一个可以搜索公众号、视频号内容的入口,微信的AI搜索就有了一定独特性。

来源:新榜《2023企业新媒体矩阵营销洞察报告》
对于B2B行业来说,这一点更加重要。微信公众号、视频号以压倒性优势成为了企业社媒的TOP1窗口。[5]

来源:KAWO《2024年B2B社媒营销研究报告》
从网站类型来看,在线服务、教育、文娱媒体、科技互联网,都是ChatGPT导流最直接的受益者。[6]

而我们拿到的数据表明,这些类目与微信搜索中最活跃的类目高度重合。

来源:腾讯广告官方资料
格外利好长尾内容和中小企业
从传统搜索引擎排名的角度来看,“权重”才是真正的血脉压制 – 权威、知名的网站天然受到算法青睐,在一些主流话题上,中小企业基本拿不到好排名,也就没有流量。一些优质、小众的内容,在传统机制下恐怕难有出头之日。
但AI搜索能够很大程度的改变这种情况,以用户需求和体验作为更高的标准,而不是按照权威度排资论辈。
即使你在大众意义上不出名,但也有可能是某个细分领域的专家、某些垂直类目的TOP1产品,你就是最懂用户的。那么,你创作的内容就有可能被AI作为最高优先级向用户展示,从而获得大量精准流量。
研究显示, AI搜索给中小网站带去的流量占比,甚至比大网站要高很多。[7]

虽然我们还没有拿到微信AI搜索的内测资格,但早就在腾讯出品的“元宝APP”上尝试过搜索功能。结果显示,“增长黑盒”这个公众号的内容,的确能够在某些垂直话题内获得良好的展示,甚至一些主流热门话题也可以(我们并不出名,对吧?)。

流量的商业价值更高、更多元
AI对于搜索的加成作用会呈现两个极端:一部分用户想要快速简洁,但也有不少人希望深度专业。吸引后一类用户的商业价值明显更高,因为他们更有可能对高客单价品类/服务、B2B专业领域感兴趣。
一项针对头部B2B官网流量的研究发现,2024年AI搜索带来的流量竟然增长了500%!按照如此势头建模预测: 三年后,B2B官网的流量将有50%以上来自AI搜索。[8]
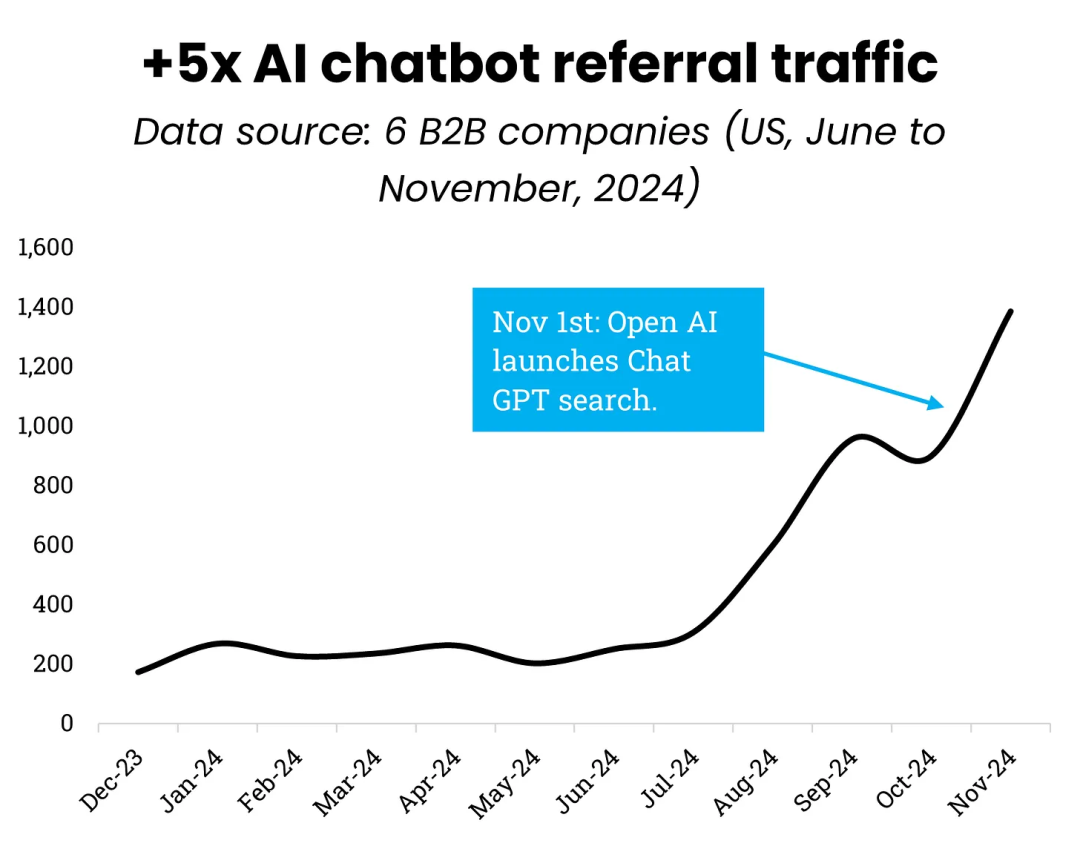
我们再从日常消费的角度来看流量价值。一项针对交易类流量的研究显示(主要是amazon、ebay、etsy等电商网站): 通过AI搜索进入电商页面的用户,会比google来的停留时间更久,并且访问更多的页面内容。较长的会话持续时间结合较高的页面浏览量,意味着用户在评估产品时花费更长时间、购买的兴趣更高,显然可以总结为流量的质量更高。[9]

另外一个值得注意的现象是:用户似乎不再满足于图文类的内容,流量价值评估更加多元化了。
比如目前ChatGPT导流最多的地方是youtube,占比从2024年7月的0.17%提升到9月的3.9%;而amazon电商导流从0%增长到了1.1%。[10]

如果未来微信的AI搜索能够引入视频号直播、私域导购、B2B小程序落地页、小程序电商商城,想象力还能再上一层楼。
那么,整个AI搜索创造的增量规模会有多大?这里我们需要冷静看待。
数据显示,仅仅通过ChatGPT联网功能给其他网站带来的流量,三个月增长了60%,每天都有上百万流量从ChatGPT导向外部网站。而从ChatGPT收到流量的独立域名数量,则翻了3倍。[11]

然而,众多研究也表示,从整个互联网来看,目前AI搜索引擎给网站贡献的流量虽然增长快,但可能不足网站总流量的1%。只有在一些特定的行业或垂直领域,这个比例有可能超过5%,甚至能达到20%。当下通过AI搜索来获得用户增长,更像是“出奇制胜”,而非“颠覆传统”。
AI搜索并不是像短视频一样全民爆发的机会,一方面需要时间慢慢积累,另一方面内容的独特性也是必备条件。知名研究机构Gartner预测:到2026年,传统搜索引擎的流量将下降 25%,搜索营销将把市场份额让给 AI 聊天机器人和其他虚拟助手。[12]
那么企业在AI搜索趋势发展之初,应该提前进行哪些策略规划,并尝试落地呢?其实,如何从AI搜索中获得流量增长,是过去1年国外数字营销领域最热门的话题。由此也诞生了一个概念:Generative Engine Optimization(GEO)。
GEO指的是优化网站上现有的内容,以使其更适合被语言学习模型(LLM)扫描并用作来源,让更多用户能够在AI搜索中发现内容并点击访问网站。与传统的搜索引擎优化(SEO)主要关注关键词和网站结构不同,GEO更侧重于内容的深度、用户意图和语义相关性,确保内容既能满足用户需求,又能被AI引擎有效识别和利用。
下图展示了如何通过GEO让一家披萨店网站出现在AI回答的最高优先级,替代知名的纽约中央公园。[13]

一篇最新的论文显示,通过GEO方法,能够将源内容可见性在AI搜索引擎中提高40%,也就意味着网站增加4成的流量机会。[14]
Gartner同样预测,到2026年超过33%的网络内容将是以生成式AI搜索为目的而创建的。[12]
当然GEO的实施策略非常复杂,也有一定的方法论。这里不再展开,仅做抛砖引玉,大家感兴趣可以在公众号后台回复关键字“GEO”领取论文完整版。
商机2:
达人营销和搜索广告有机会提升付费流量效率
问题来了:如果你是一家大公司的CMO,更想要的东西必然是“大投入、大回报”,而不是中小企业眼中的“取巧”。因此,只有微信的AI搜索能够通过付费投放,获得规模化、稳定的增长,才具备增量的价值。
这其中能有什么机会呢?
我们认为,平台的新入口是否有资格被称为“流量红利”,关键点在于这个入口能否让平台自己赚到钱。毕竟,注重用户体验不等于做慈善,一个无法商业化的能力难免会沦落为边缘功能。
用互联网黑话来说,这就是流量“货币化率”的程度。微信内无论是朋友圈、视频号、公众号,广告加载率一直是很低的,微信中其实有大量的流量无法被货币化。
AI搜索如果能够重新利用这些流量,提升货币化率,那才有真正的想象空间。
带动达人营销生态发展
以下是我们的推测:AI搜索给微信带来的真正潜力在于达人营销。
腾讯其实早就推出了一个对标小红书蒲公英、巨量星图的广告产品,叫做“腾讯互选广告平台”,就是官方进行达人筛选和投放的通道(没错,我们也是互选平台的优选达人)。最近两年随着视频号崛起,发展非常快。
微信内无法被货币化的流量掌握在谁手里?肯定是各种公众号、视频号的达人,甚至是私域社群的群主 – 微信有5000万创作者。
接下来,我们根据下面这张图,推理一下逻辑:
如果微信AI搜索的体验更好,必然有更多人用
用户能够发现更多达人内容,从而给达人带去了流量
更多原生达人能成长起来,其它平台的达人也愿意迁移过来
品牌看到了这些增量的优质内容,愿意花钱投放给达人,也能获得更好的回报
达人赚了钱,有动力生产更多优质内容,AI搜索的质量更高、体验更好,用的人就越多
平台赚了钱,更愿意投资AI技术、扶持达人、完善商业化产品
整个闭环形成

这种看似“曲线救国”的方式,实际上抓住了内容平台最核心的资源 – 优质内容。比起自己付费买搜索流量,广告主其实还有其它的选择:直接把达人们积累的自然流量买过来不就行了!
我们在2024年Q4的调研显示,无论是微信视频号还是公众号,用户增长的驱动力TOP1就是内容的匹配程度,这点跟抖音和小红书有明显差异。“内容质量上升”这一驱动力,在微信内容生态内的表现较为显著。
也就是说,现在微信急需构建有特色的达人生态,来维持用户的增量,然后才是吸引广告主投放预算。

而这些达人种草内容,的确能够引发用户积极的后链路行为 – 这是广告主最乐意看到的。
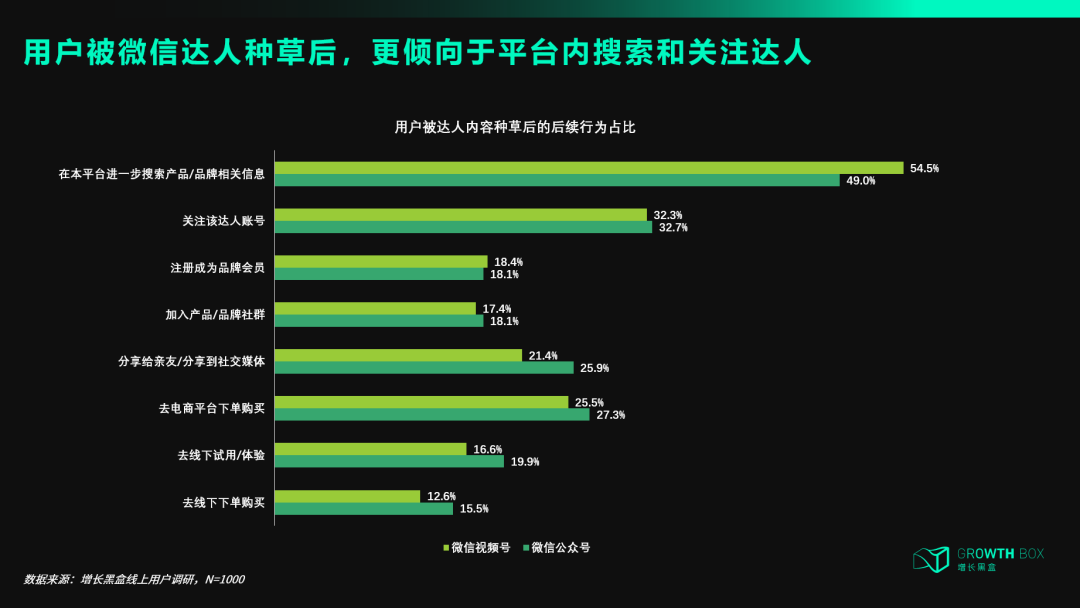
根据我们拿到的一些内部数据来看,微信内容生态的增长还是比较正向的 – 这进一步验证了我们的逻辑推断。


在搜索结果中引入广告
这是一个非常简单粗暴的做法,与传统搜索引擎变现的模式并无差别,但增加了广告位,从而带动广告加载率提升。
2024年10月,Google率先做出大胆的商业化尝试:在AI搜索结果中加入广告,并在美国手机端正式上线。
Google搜索中早就上线了一个名为“AI overview”的功能。这相当于在传统的Google搜索结果页面的最上面,增加了一个区块来展示AI对于搜索结果的总结。原本这里是没有广告的,但现在部分商品广告会出现在里面。比如用户搜索如何在洗衣服的时候去除褶皱,那么AI Overview中不仅有教程,还有洗衣液的产品广告。[15]

AI overviews并非百分之百展现,而是根据搜索关键词的不同,有选择性的出现。有调研显示,去年8月时差不多有12.47%的搜索结果中包含AI Overviews,比前几个月有了大幅增长,但从整体广告加载率的角度来看肯定是很低的,Google也处于尝试阶段。[16]

但至少Google的内部调研显示:用户认为这些广告有帮助,因为它们能在自己需要时迅速将其与相关的企业、产品和服务连接起来。[17]
反观国内,目前基本无人敢迈出这一步,各大AI搜索工具主打的都是“无广告”。这甚至倒逼百度在年初推出AI搜索功能时,也把“无广告”作为了卖点。
所以,按照微信一贯的保守作风,也不会这么早就把AI搜索本身商业化。
比如昨天,有知名博主指出,腾讯元宝中AI回答的结果可能存在广告链接。腾讯公关总监张军马上出来辟谣“理论上不应该”。

结语
搜索原本是一个主动在信息的汪洋大海中寻找有用线索的过程,传统的SEO主要依靠搜索词/点击量等表层数据来实现。而对于微信生态来说,由于它早已渗透进人们日常生活的方方面面,接入AI后,搜索很可能会实现千人千面的效果。
我们大胆推测,当一个用户在微信搜一搜里搜索“度假”,搜索结果不再是全网点击率最高或是最新发表的帖子,而是DeepSeek在排除隐私信息后,分析了该用户的公众号阅读习惯、视频号点赞内容、小程序访问记录等,综合给出的最优方案。
我们认为,微信接入DeepSeek将会深刻重构流量分配的逻辑,所以对于品牌营销而言,不仅需要强化内容质量与关键词优化以提升索引权重,还要紧抓达人已有的高质高效流量,找到自己的精准用户。
当公众号、视频号及全网数据搭配上「深度思考」,品牌营销的目的或许不再是占领消费者心智,而是成为时刻陪伴消费者的智能化伙伴。
参考资料:
[1] 微信搜一搜月活跃用户达8亿,“数据看板”如何助力精细化运营?|新京报
[2] Bill Gates on possibility, AI, and humanity|Youtube
[3] 63% of Websites Receive AI Traffic (New Study of 3,000 Sites)|ahrefs bolg
[4] 《2023企业新媒体矩阵营销洞察报告》|新榜
[5] 《2024年B2B社媒营销研究报告》|KAWO
[6] Investigating ChatGPT Search: Insights from 80 Million Clickstream Records|Semrush Blog
[7] 63% of Websites Receive AI Traffic (New Study of 3,000 Sites)|ahrefs bolg
[8] How significant is AI chatbot traffic in B2B?|Growth Memo
[9] Transactional AI traffic – a study of over 7 million sessions|Growth Memo
[10] Chat GPT Search|Growth Memo
[11] Investigating ChatGPT Search: Insights from 80 Million Clickstream Records|Semrush Blog
[12] Gartner
[13] What’s Generative Engine Optimization (GEO) & How To Do It (Source: https://foundationinc.co/lab/generative-engine-optimization)
[14] GEO Targeted: Critiquing the Generative Engine Optimization Research|sandboxseo
[15] Google Search’s New AI Overviews Will Soon Have Ads|WIRED
[16] AI Overviews Research: Google Ads in the AIO-inclusive SERPs|SE Ranking
[17] New ways for marketers to reach customers with AI Overviews and Lens|Ads & Commerce Blog
来源:钛媒体