大年底的,豆包又轰动了一把。
今天,豆包 APP 宣布全新端到端实时语音通话功能正式上线,不玩「预发布」,直接全量开放、人人免费使用,迎接每一个用户的检验。
豆包实时语音大模型网址:https://team.doubao.com/realtime_voice
看完后,我们发现有几个很妙的点:
首先,豆包真的很像人,遣词造句、语气和呼吸节奏都高度拟人化。你压低音量说话时,豆包也会使出「悄悄话」技能,完全消除了以往 AI 语音通话的人机感。
其次,不管中文对话的复杂度如何,豆包都能顶得住。经过我们一系列实测体验,豆包在中文能力方面可以说是断层式领先。这个优势不只是相比于 ChatGPT 等海外选手,对比一系列国产 AI 对话类应用也是这样。
此外,豆包是一个上知天文下知地理的「聊天搭子」。它是认真在听用户说的话以及想要表达的深层含义,会迅速给出有趣又有用的回复,而且有联网查询能力。
要想体验这项功能,需要将豆包 APP 升级至 7.2.0 新春版本。上线后,大量用户第一时间更新、涌入,和豆包煲起了电话粥:
还记得在 2024 年 5 月 14 日凌晨那场直播中,GPT-4o 横空出世,带给 ChatGPT 全新的实时语音通话能力,业内称之为「震撼全球的发布」。遗憾的是,这项功能在 ChatGPT 全面上线后,我们的实际感受却并不像发布会演示那样印象深刻。
现在,轮到豆包震撼世界了。上线之前,内部团队已经围绕拟人度、有用性、情商、通话稳定性、对话流畅度等多个维度,对这项功能背后的豆包实时语音大模型和 GPT-4o 进行了考评。整体满意度(以 5 分为满分)方面,豆包实时语音大模型评分为 4.36,GPT-4o 为 3.18。其中,50% 的测试者对豆包实时语音大模型表现打出满分。
此外,在模型优点评测中,豆包实时语音大模型在情绪理解和情感表达方面优势明显。尤其是「一听就是 AI 与否」评测中,超过 30% 的反馈表示 GPT-4o 「过于 AI 」,而豆包实时语音大模型相应比例仅为 2% 以内。
接下来的部分是机器之心的实测,如果你看完感兴趣,建议赶快打开自己的豆包 App,将版本升级至 7.2.0 新春版即可体验。毕竟从目前的火爆程度来说,去晚了可能有挤不上车的概率。
在 2024 年底,豆包大模型团队就透露了会很快上线豆包 APP 的全新端到端实时语音功能,引发了一大波用户的期待。
真正用上之后,我们的感觉是:它的拟人程度和自然程度的确超出想象。
非常擅长感知、承接人类用户的情绪,是豆包的一大亮点。不妨听几段我们和豆包的对话,感受一下它的拟人程度。
比如情绪表现能力,让它在声音中表现出复杂情感,可做到「人机难辨」的程度。
豆包仿佛是一位演技精湛的演员,面对 500 万元彩票的不同场景,时而欣喜若狂,时而悲痛欲绝。
指令遵循能力也很强。我们怎么 PUA 豆包用各种语速去背诗都能做到,而且还会自己感受诗文中的情绪,有感情的背诵。
共情能力也是拿捏了。我们第一句话是带着沮丧的情绪讲述坏消息,豆包就会用比较平静温暖的语气来安慰你。但当你恢复了积极心态,转换为轻松的语气夸奖它,豆包就会切换为活泼的语调。它也会有类人的副语言特征,包括语气词、迟疑、停顿等。
与此同时,我们能感受到,豆包不只是提供情绪陪伴,比如在第一场对话测试中,它给出的抢票建议、行程推荐也是非常实用,关于天气等即时信息,也能迅速检索到准确的结果。
是的,豆包侃侃而谈的背后是基于豆包实时语音大模型强大的语义理解能力和信息检索能力。在用户语音输入时,豆包马上开始对各维度信息进行深度理解,保证输出信息的有用性与真实性。通俗地说,就是既有「情绪价值」,也有「实用价值」。(不过我们也发现,豆包实时语音大模型目前只支持中英文,期待未来多语种能力可以强化一波。)
既然豆包长期「混迹」互联网,玩抽象的水平一定不会差。
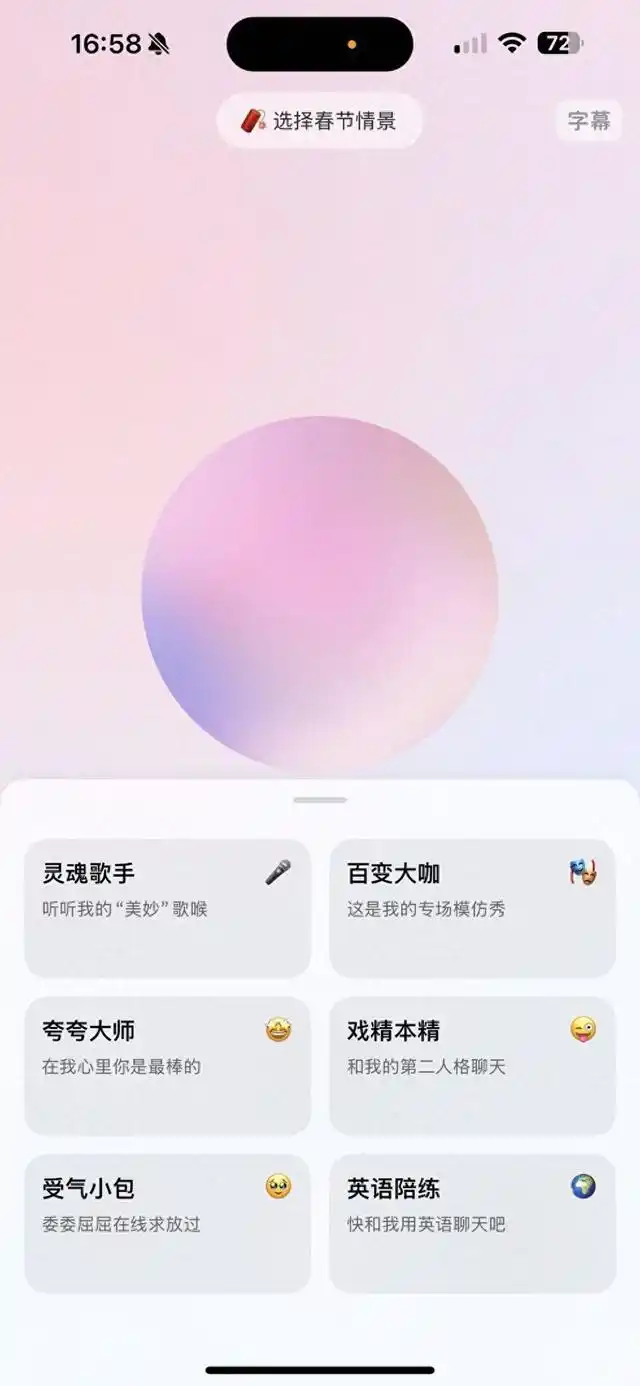
当然,和豆包对话,你拥有的不只是一个搭子,而是无数个戏精朋友。
在「百变大咖」模式下,从孙悟空到林黛玉,从灰太狼到懒羊羊,对声音的控制和对情感的演绎,让豆包的用户体验更上了一层楼。
既然角色扮演不在话下,讲故事能力也手拿把掐。在恐怖与搞笑之间,自由切换。
有意思的是,豆包 APP 推出了 GPT-4o 没有的唱歌功能,这是一个老少皆宜的玩法,爆火指日可待。
年底了,我们就让它来一些拜年歌曲吧,作为这次测评的收官之作:
遥遥领先的通话体验,背后是哪些技术?
如此丝滑、自然的实时语音通话,豆包背后的团队是如何实现的?
为这项功能提供核心能力支持的是近期推出的豆包实时语音大模型。
据豆包大模型语音团队介绍,这是一个真正实现端到端语音对话的语音理解和生成一体化模型,比传统级联模式,在语音表现力、控制力、情绪承接方面的表现更惊艳,并具备低时延、对话中可随时打断等优点。
放眼语音 AI 相关领域,面向真人级的实时语音大模型,技术难点有二。
其一是,情商与智商之间难以平衡。
语音领域不少从业者都知道,模型自身在对话自然度、有用性及安全性维度经常存在着此消彼长的矛盾关系。换而言之,就是如何能让模型既是逻辑推理能力在线的 「学霸」,也能表现力、共情力、理解力在线,情商水平拉满。
据团队介绍,他们面向上述问题,在数据和后训练算法方面,确保了多模态语音对话数据兼具语义正确性与表现力的自然性。同时,依靠多轮数据合成方法,生产高质量、高表现力的语音数据,确保生成语音表达自然且一致。
此外,团队还定期对模型进行多维度评测,依托结果及时调整训练策略和数据使用方式,确保模型在智商和表现力之间始终保持良好平衡。
其二是落地门槛高,欲让语音功能不止步于 Toy,对团队综合能力是一大挑战。
在以往,包括 GPT-4o 在内的一众端到端语音发布只是展示 Demo,即便后续能力公开,实际能力也未必被大众认可。原因在于:功能研发过程中需要算法、工程、产品、测试等团队参与,既要明确用户需求、又要划分好技术测评维度和指标,此后在模型训练、微调等过程中,同样需要多个团队密切配合。最后,当产品若想上线服务亿万用户,还面临极大工程落地、安全方面挑战。
前文提及,本次豆包官宣的全新实时语音功能上线即开放,直接服务于万千用户,团队也尽可能寻找交付体验方面的最佳平衡点,在保障安全性的基础上,让模型拥有前所未有的语音高表现力、控制力和亮眼的情绪承接能力,同时,确保其既具备强大的理解和逻辑能力,又能联网回答时效性问题。
在语音生成、理解与文本大模型联合建模的框架下,团队实现了模型多样输入输出能力,同时,保证了生成侧模型在更低系统时延情况下的生成准确性、自然度,同时在理解侧,该框架让模型实现了敏锐的语音打断与用户对话判停能力。
当然,团队也非常重视模型能力提升带来的安全问题。据相关技术人员分享,他们在联合建模的过程中,于后训练阶段,引入多种安全机制,通过对潜在非安全内容进行有效压制和过滤,降低安全风险。
技术团队还向我们透露,经由联合建模,模型令人惊喜地涌现出指令理解、声音扮演和声音控制等新能力。举例来说,目前模型部分方言和口音,主要源自于 Pretrain 阶段数据泛化,而非针对性训练。在这一点上,语音模型和语言模型非常相似。
惊喜之外,豆包「颠覆」了什么?
在目前已有的同类产品功能中,我们能感受到:豆包的拟人度、情感化体验是最好的,十八般武艺样样精通,在中文能力上更是远超 ChatGPT 等「舶来品」。
看到最后,可能有人想问:除了惊喜的用户体验之外,为什么豆包更新的端到端实时语音收获了如此多的关注?
关键答案是:它是第一个服务于亿万用户且真正 Work 的端到端中文语音系统 —— 好用,且免费用。
曾几何时,与 AI 进行实时语音对话只是一种科幻电影的场景,也是我们对高级人工智能的一种具体想象。但现在,这样的神奇功能就存在于你我手机中的豆包 APP,从「遥遥相望」变得「触手可及」。
简单总结,豆包的全新端到端实时语音开创了两个先河:
从技术变革的层面看,豆包业内首次地给 AI 注入了「灵魂」,做到了「情商」和「智商」的双商在线。这似乎意味着传统语音助手时代的结束。我们已经不再下意识觉得自己是与一个被海量数据训练的模型说话,人和 AI 开始产生了微妙的情感连接,包括信任、依赖,科幻电影的情节正走进大众生活。
正如《Her》等经典作品中,人类之所以爱上 AI,从来不是因为它能提供无限的知识,而是因为它能带来恰到好处的情感价值。
从大模型技术落地的层面看,端到端实时语音通话补齐了多模态交互方式中为数不多的空白。大模型应用的玩法正在不断升级 —— 未来的产品可能是接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合输出。人和机器的交互方式正在被颠覆,进而变革人与人的交互方式。
至少对于当前的中文用户来说,豆包端到端实时语音功能的上线提供了一种以人类自然语言为媒介的交互方式,真正打破了人们获取、体验高级人工智能的门槛。
回到半年前,我们能想象到是豆包率先创造了历史吗?
从 2023 年的大语言模型开始,到 2024 年结束,豆包大模型家族在图像、语音、音乐、视频、3D 等多模态层面均已补全,不仅在国内跻身第一梯队,也在短短几个月的时间里完成了从「初出茅庐」到「震撼世界」的蜕变。
而在百舸争流的大模型赛道上,谁先抵达这一里程碑,或许就决定了其未来十年在领域内的排位。
接下来一年里,关于大模型、关于豆包和国产 AI 将以怎样的速度前进,更加值得我们期待。